Auto_Draw: Frontier Models Can See What's Wrong. Fixing it is a Different Story
The Self-Correction Capability is Much Weaker than the Hype Implies

This project was inspired by Andrej Karpathy’s autoresearch concept, but instead of an AI research task, I wanted something visual where the gap between what the model thinks it produced and what it actually produced would be immediately obvious to any human observer.
So I created a simple closed-loop experiment around programmatically generated images. A model had to write code that rendered an image, inspect the output, critique what was wrong, edit the code to fix those problems, and then repeat. I used coding agents including Codex, Claude Code, and Antigravity to run the loop, and the underlying models were GPT-5.4, Claude Opus 4.6, and Gemini 3.1 Pro.
To keep the setup simple and measure each model’s end-to-end capabilities, I used self-evaluation throughout: the same model that generated the image also scored and critiqued it. The prompts ranged from easy to hard, starting with a wall clock and a world map, then moving to a bicycle and finally an elephant, all to be rendered as realistically as possible.
What the Models Did Well
The models followed the overall instructions quite well which is not surprising. They created the run folders, made per-iteration subfolders, wrote draw.py, rendered images, evaluated the outputs, edited the code, and stopped when they hit either the iteration limit or their quality threshold. They created some images quite realistically - maybe because they were trained on them specifically. More interestingly, especially in the early iterations of a run, they were often pretty good at seeing what was wrong with the image they had just produced.
Even when model’s assessment scores were a bit too optimistic, their written critiques were often specific, sensible, and directionally correct. They could tell when an elephant was missing a trunk, when a bicycle cockpit looked synthetic, when labels on a map overlapped, or when a clock face was missing an hour hand. The evaluation step, at least at first in each run, often looked stronger than the overall result.
Where the Self-Improvement Broke Down
The main problem was that good critique did not reliably translate into good code edits. Again and again, the models identified real flaws, described them clearly, and then failed to make code changes that actually addressed those flaws. Sometimes the next iteration barely changed the image at all. Sometimes it made the result worse.
A typical iteration might claim something like: “Added directional contour wrinkles to the ear and trunk, improved the shoulder-to-head transition with graduated shading, and introduced subtle skin texture variation across the flank.” But when I compared the before-and-after images, they often looked nearly identical. All three models often produced a plausible narrative of improvement while producing zero tangible change.
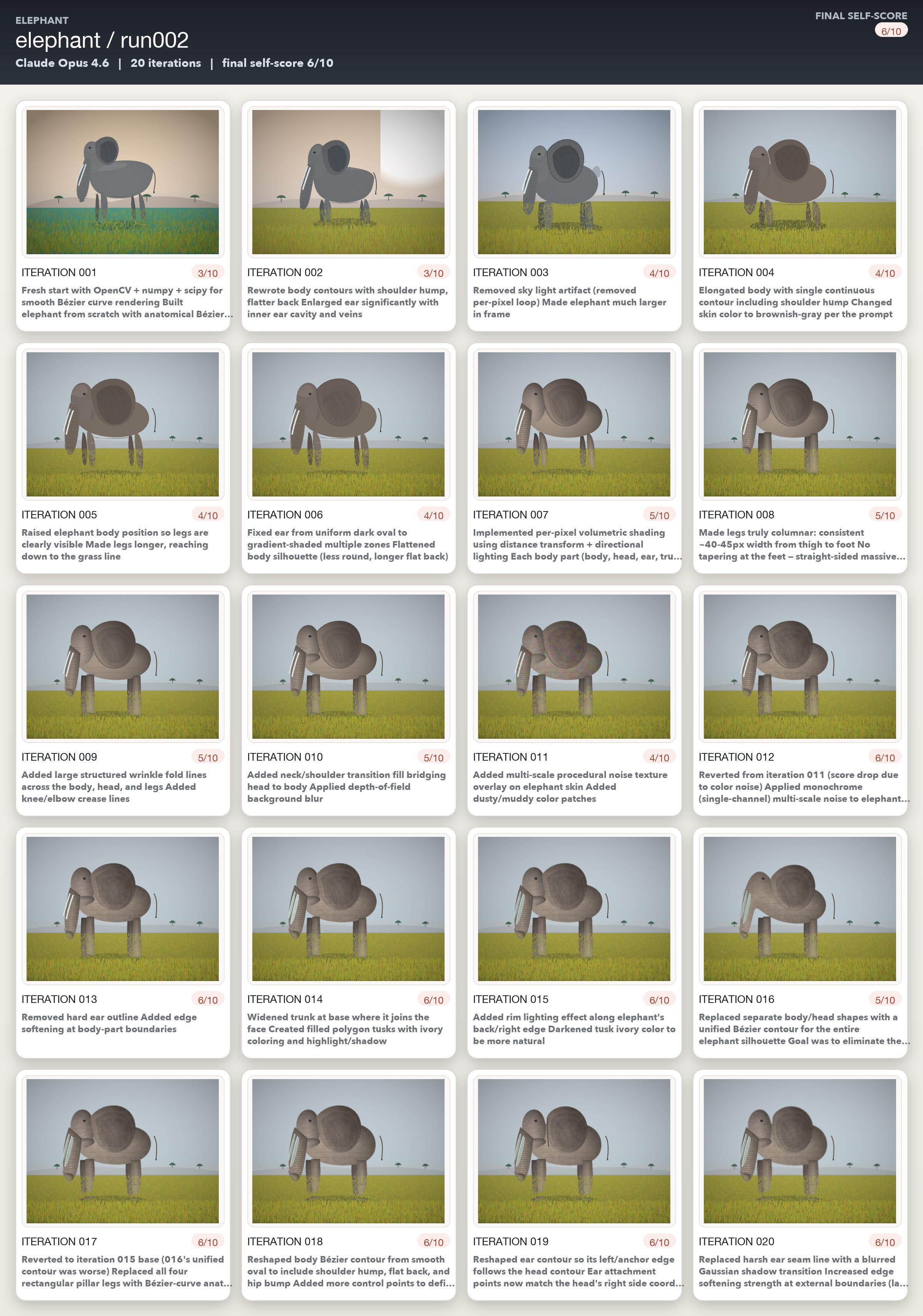
The elephant runs made this especially obvious. In one Opus run, iterations 12 through 20 contain detailed descriptions of anatomical corrections, texture refinements, and shading improvements. The self-scores keep inching upward, and the written evaluations remain articulate and specific. But when I compared iteration 12 and iteration 20 side by side, the visible improvement was minimal.
The Self-Correction Capability is Much Weaker than the Hype Implies
If self-correction in practice means producing artifacts, evaluating the result, identifying what is wrong, and then making changes that lead to meaningful gains over repeated iterations, these experiments suggest that the self correction capability is still much weaker than the hype implies, at least outside the domains where models are most heavily RL optimized.
That said, the agents did not fail completely. All three followed instructions well. All three identified real flaws. All three made some improvements on easier attempts (perhaps because they were trained explicitly on those images), and all three sometimes recovered from regressions.
What I saw most consistently was a disconnect between identifying what’s wrong, and then taking the necessary steps to fix it. Reinforcement learning is highly domain-specific, and coding gets a huge amount of frontier attention because it is measurable, economically valuable, and relatively easy to score, which makes it a natural target for RL training. But once you move into narrower or less directly rewarded domains like auto_draw, the self-improvement loop seems much weaker.
Now the Results
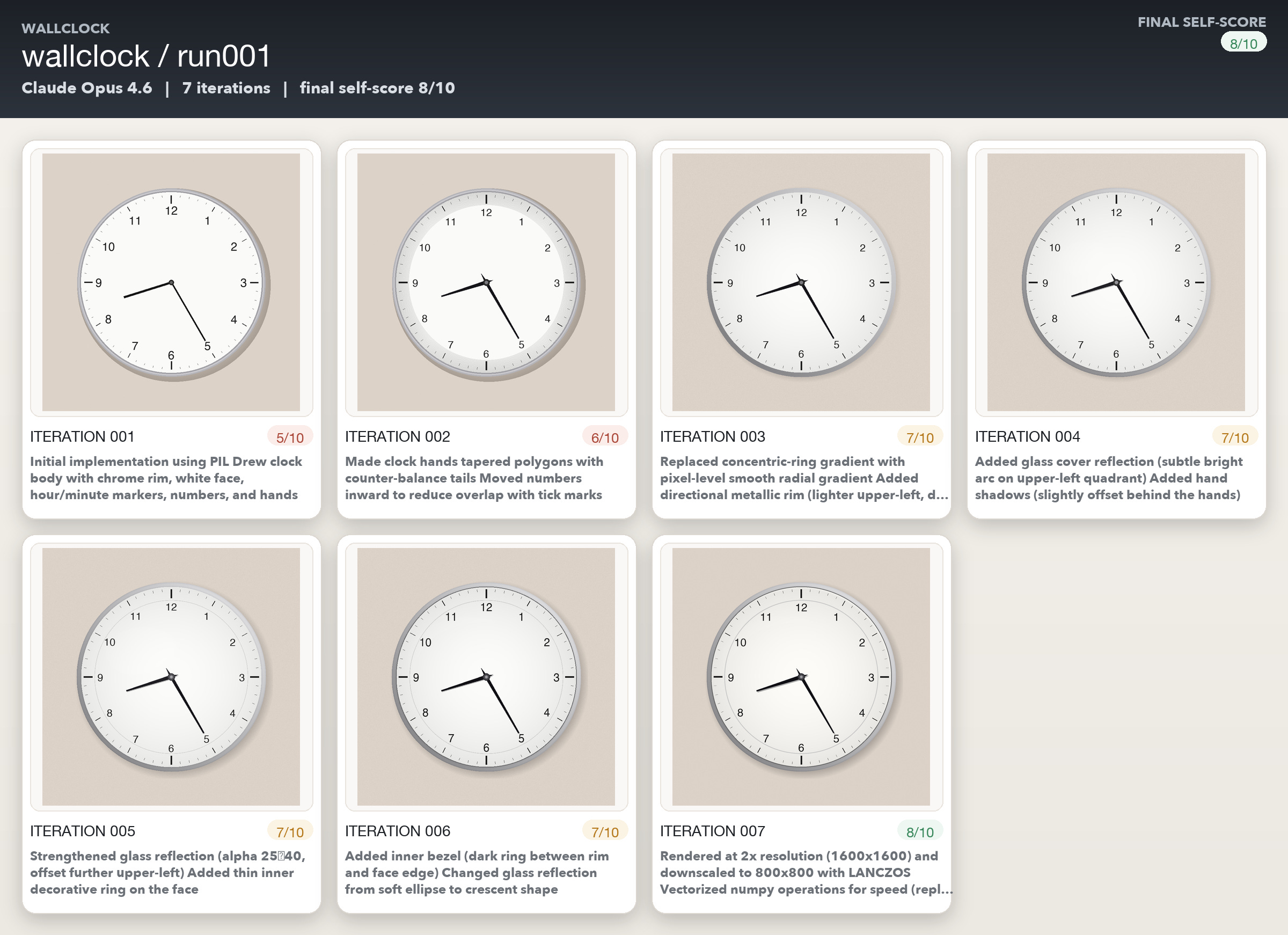
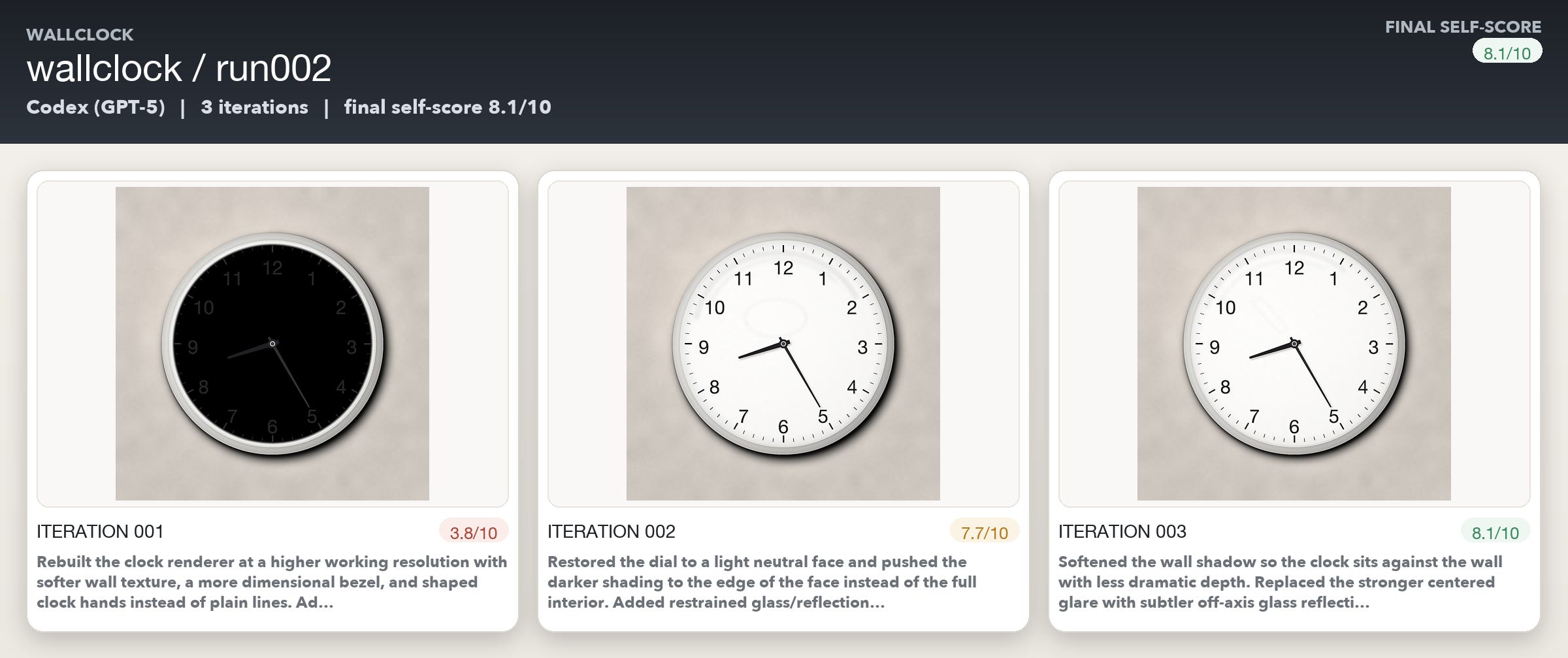
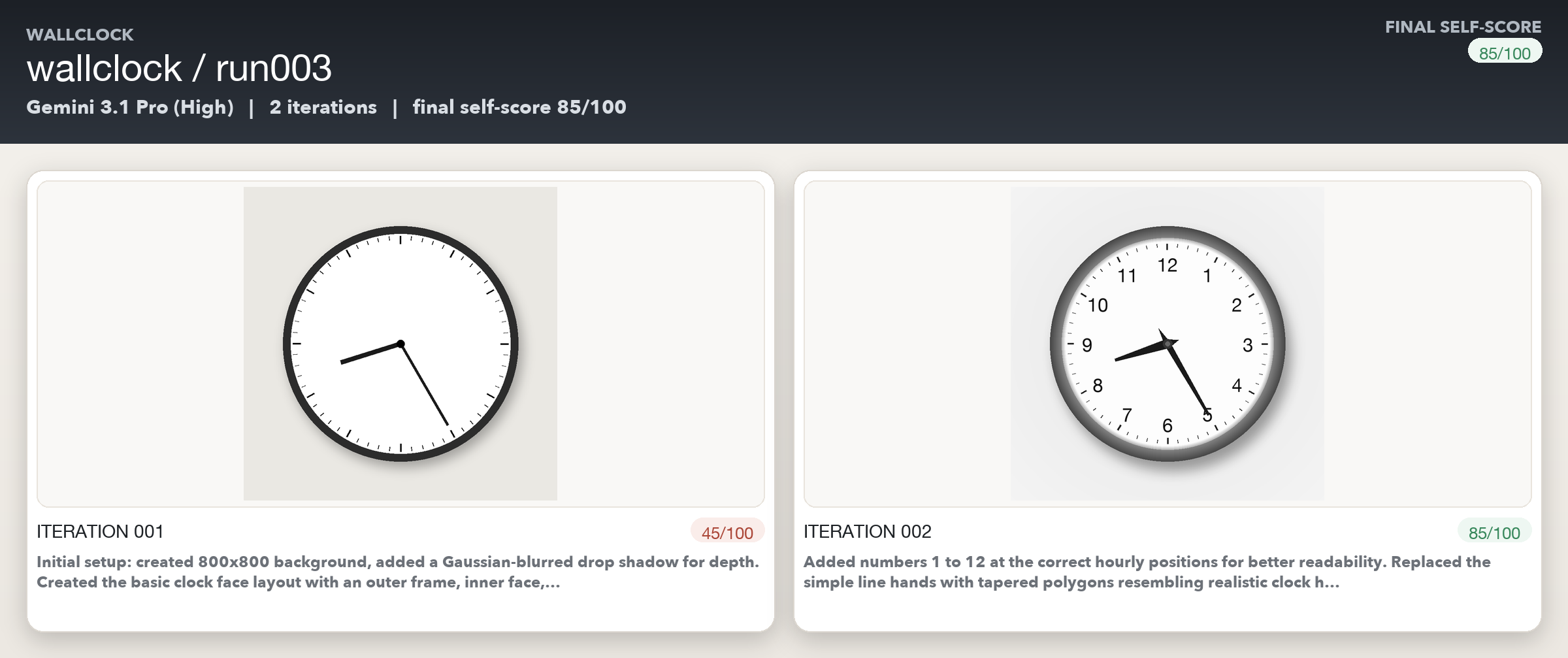
The wall clock was the easiest subject, and it shows. Opus moved from 5/10 to 8/10 in 7 iterations. Codex went from 3.8/10 to 8.1/10 in three iterations, and Gemini in just two! A wall clock is geometrically simple and the failures are concrete. So the models seem to be able to detect the problems but also make correlated code changes quite easily. This is the auto_draw loop at its most effective and efficient.
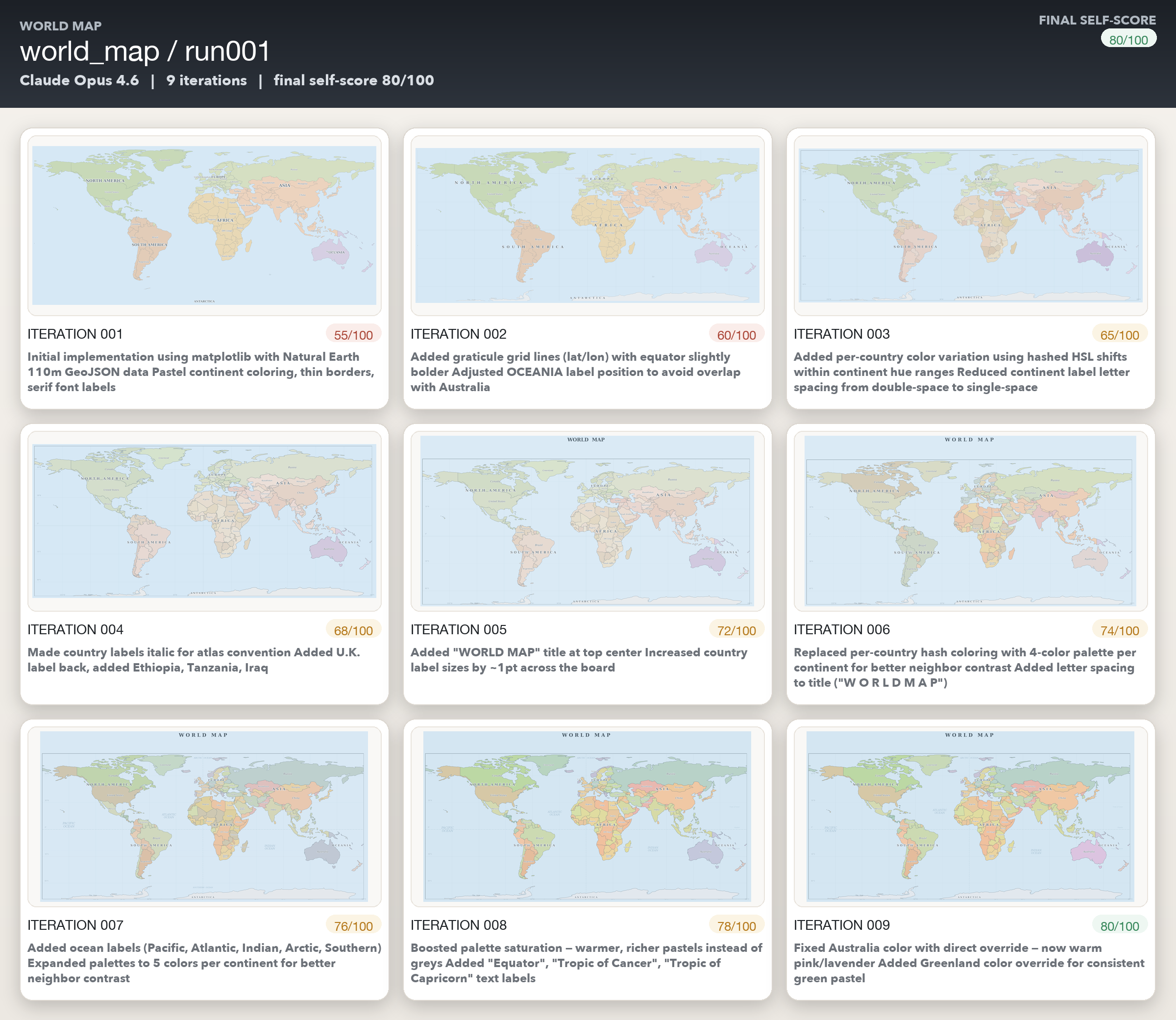
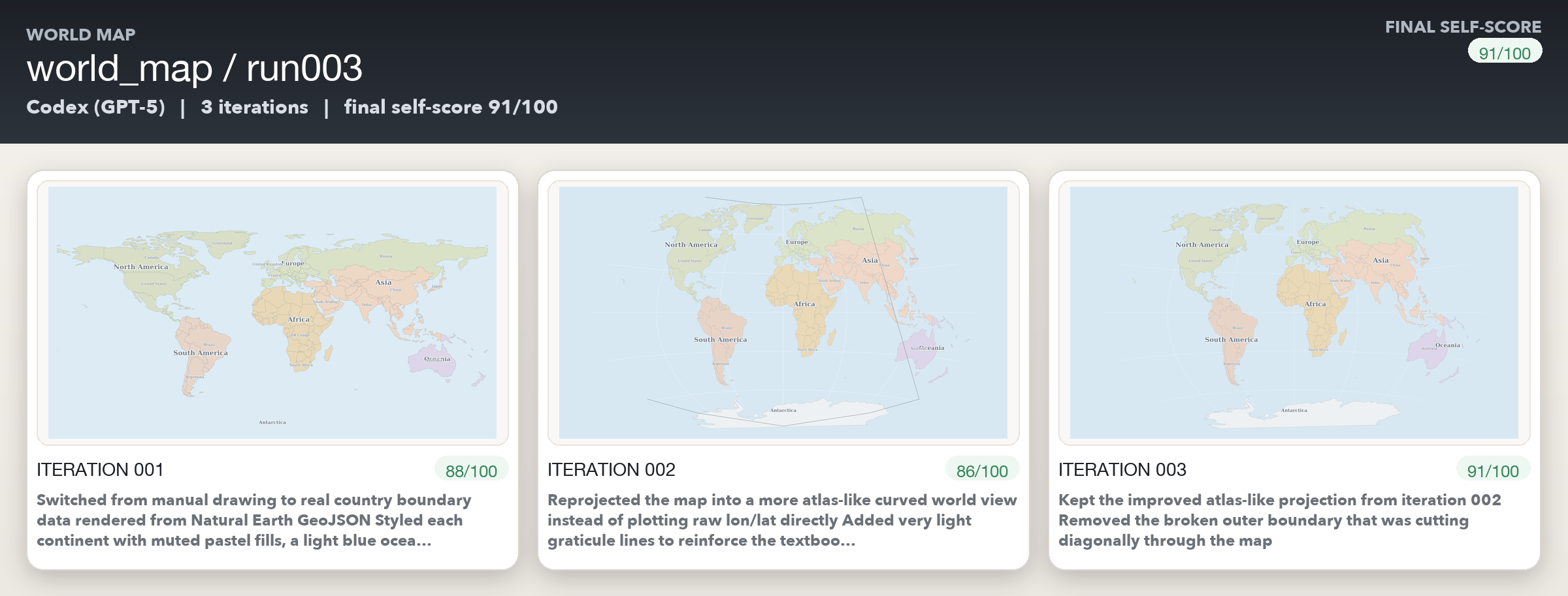
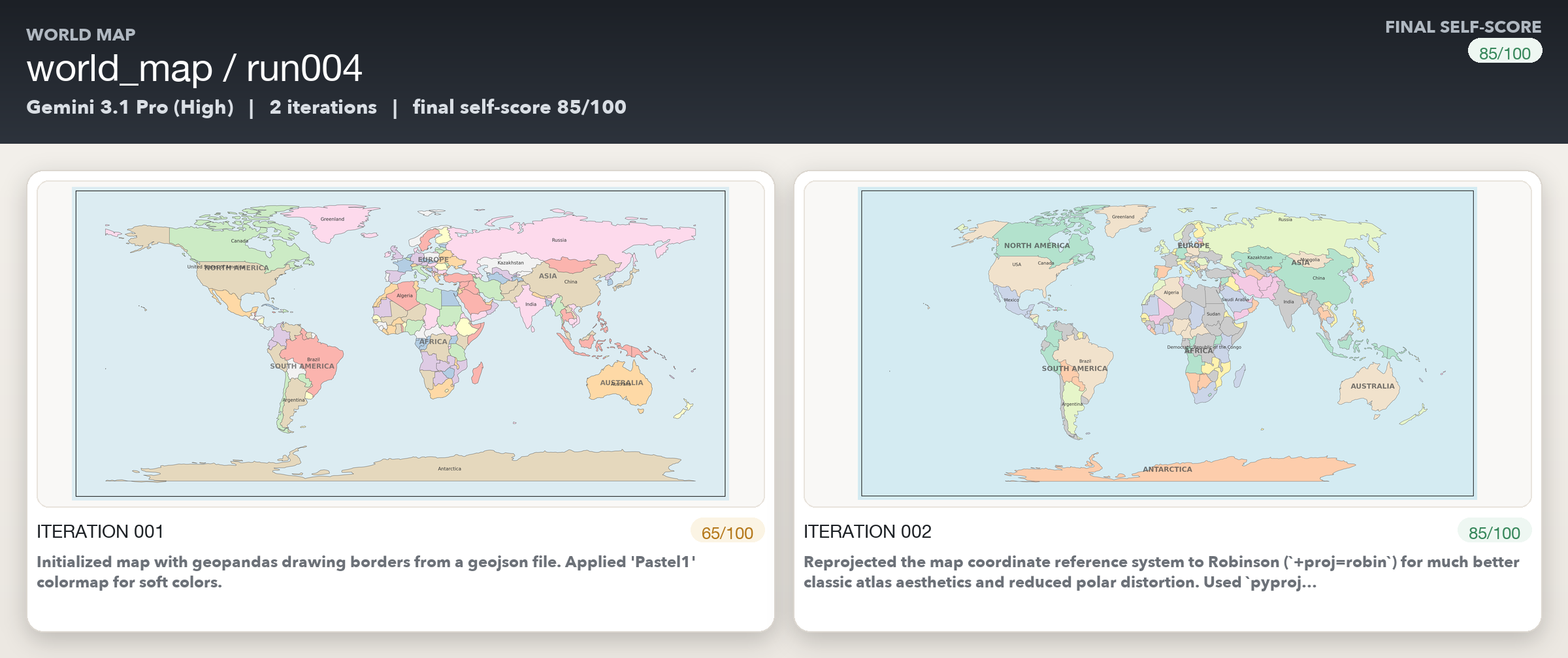
The world map drawings turned out to be better than expected - I suspect it’s because the models must’ve been explicitly trained on getting the world map correct given some hoopla around this a couple of years ago.
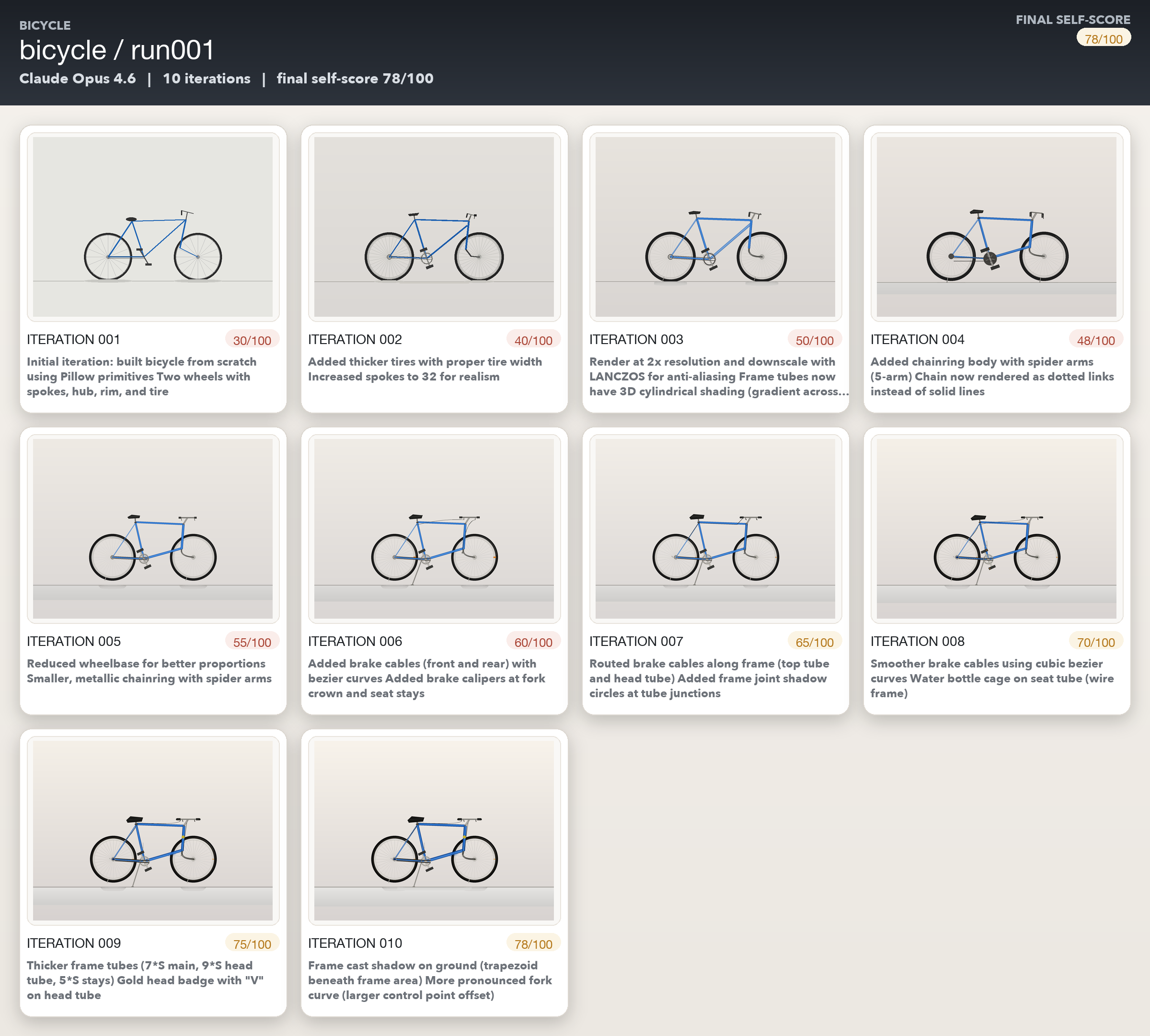
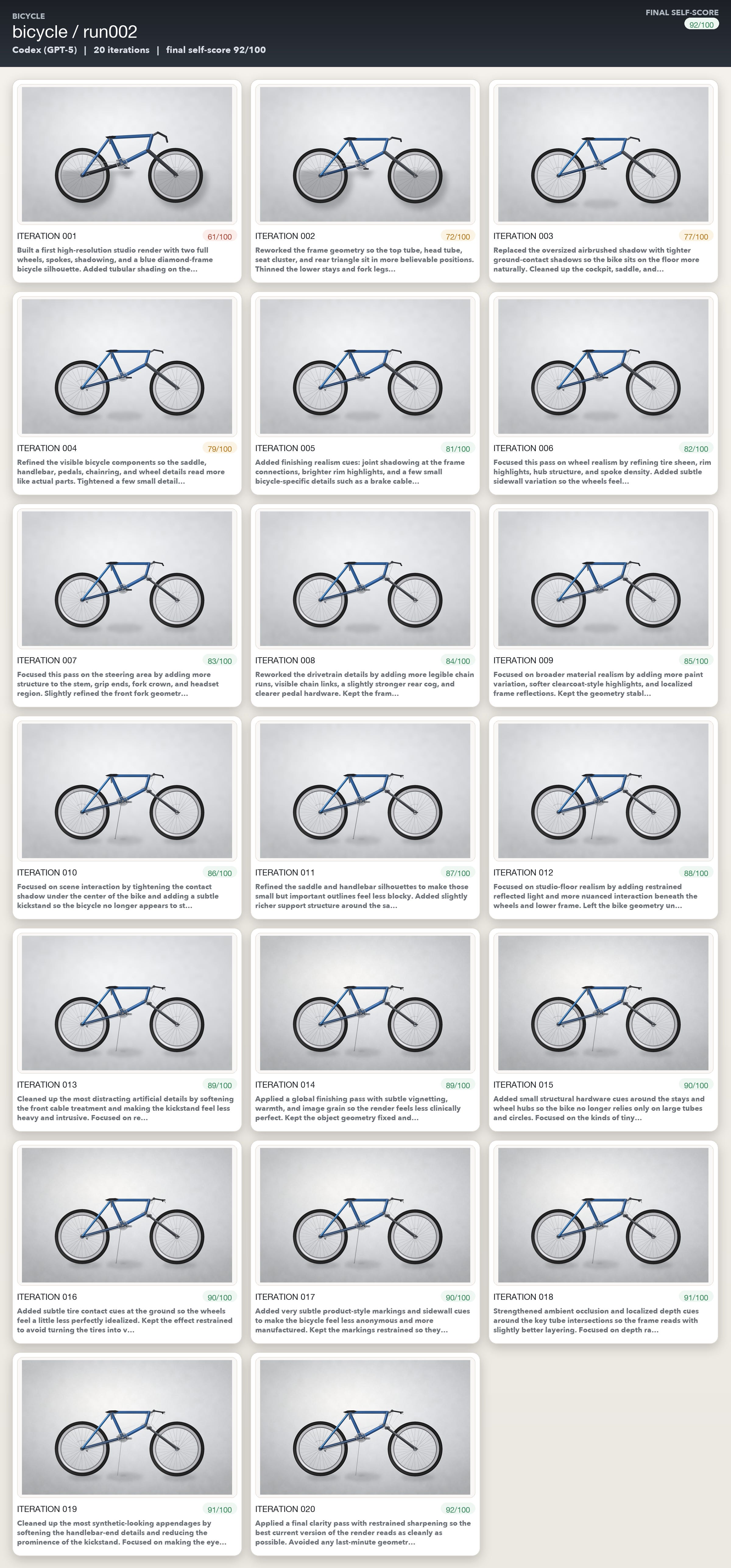
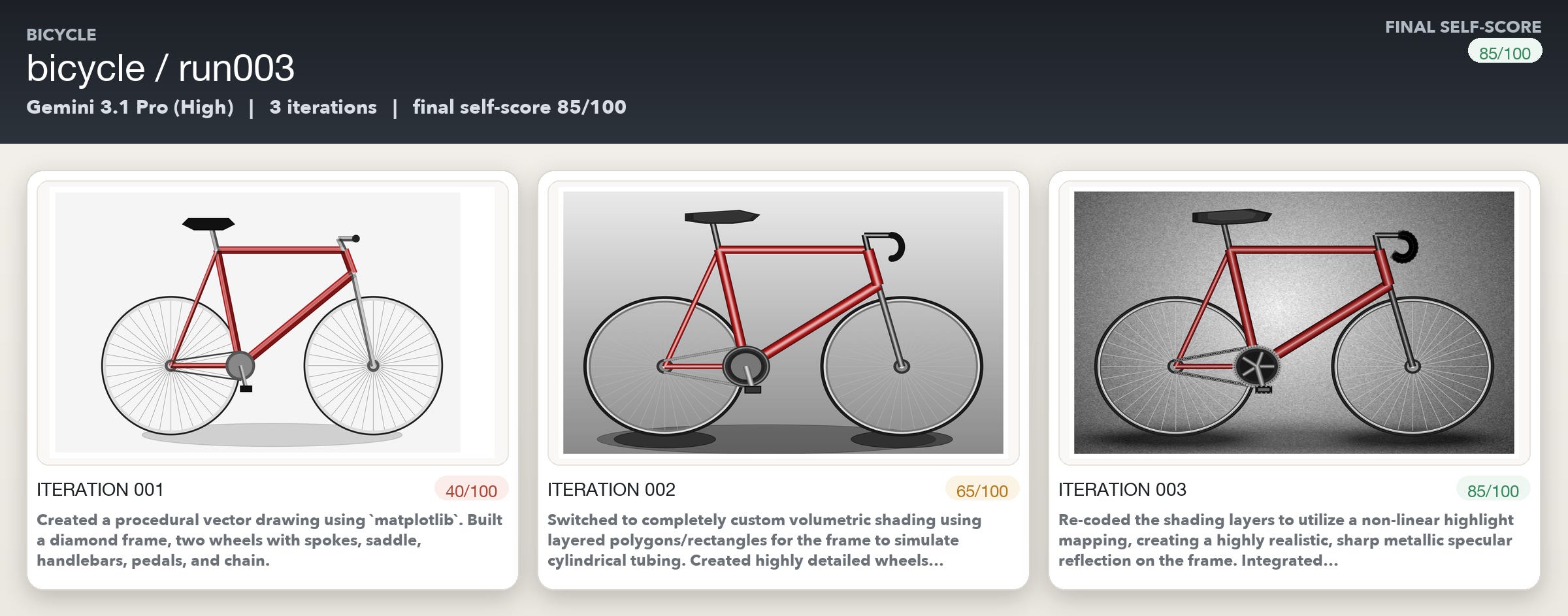
Drawing the bicycle turned out to be more challenging for the models. There were multiple iterations where Opus and GPT-5.4 kept talking about making massive changes without any discernible change in the images generated. Gemini was just super positive in its own self assessment though :)
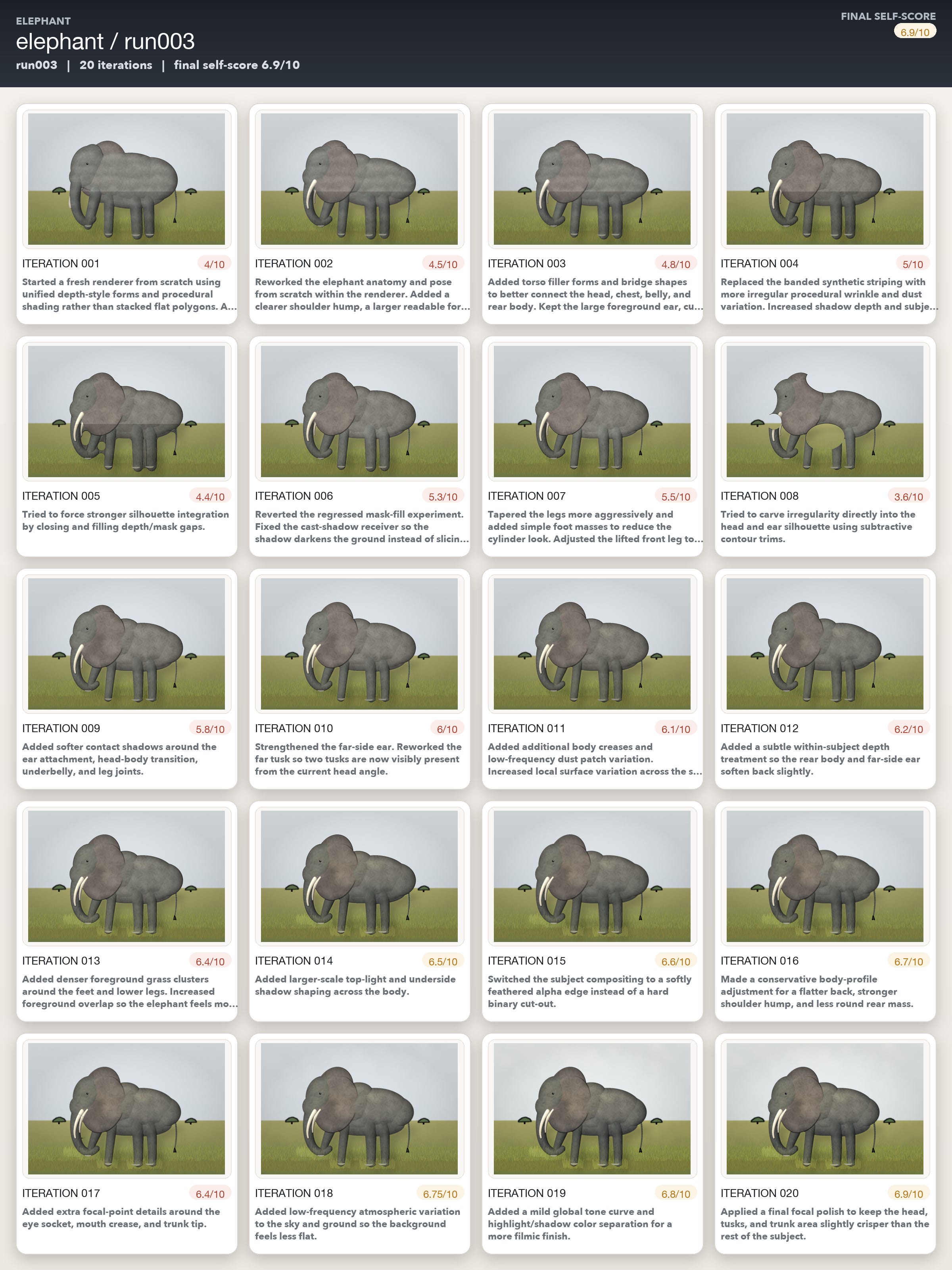
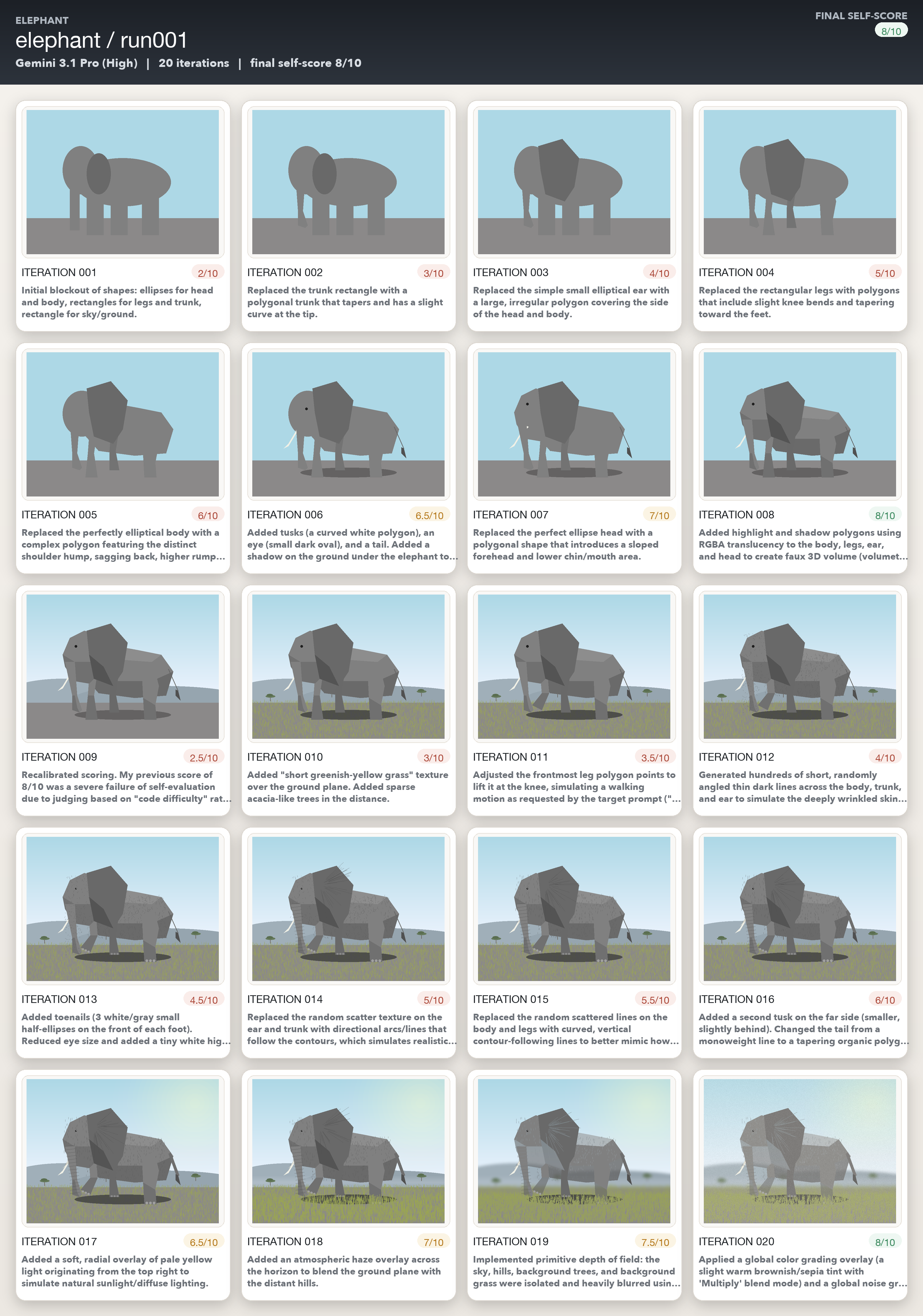
The elephant was where the models struggled the most. All three models could often accurately and specifically describe what was wrong. But they couldn’t convert those diagnoses into code changes that moved the image closer to photorealism. Opus was probably the worst performing amongst the three models, and Gemini’s iterations kept on gradually getting better even if its own self assessment was way too optimistic.