
Determinism, Truth, Creativity and Hallucinations: Untangling Often-Confused Ideas About LLMs
Why the word “determinism” keeps tripping people up (and why it matters)

Public discussions about LLMs often blur different ideas: determinism, truth, creativity and hallucinations. A recent wave of discussion starting with the publication of Thinking Machine’s Defeating Nondeterminism in LLM Inference surfaced this confusion even more. Determinism gets casually equated with truth and non-determinism with creativity and hallucinations. It’s therefore understandable that many casual followers of AI took this to mean that Thinking Machine figured out how to eliminating hallucinations and get to truth in LLMs. That’s understandable: stable outputs feel more reliable. But it’s wrong in two ways. First, a system can be perfectly deterministic and still be confidently, consistently wrong. Second, you don’t need non-determinism for a model to be creative or hallucinate.
This confusion isn't just academic; when these wires cross, people misread articles, over- or under-react to AI press releases, and make poor executive decisions.
In this article, we’ll define in plain English what each of these concepts mean in the context of LLMs. Then we’ll attempt to correct common misconceptions, each with concrete examples. As a bonus for the technically minded among you, we’ll walk through how an LLM chooses the next token, highlighting intentional variability from unintentional variability. By dissecting the journey from raw scores to the final token, we’ll pinpoint exactly where true randomness is introduced and where unintentional system quirks can arise.
Definitions
“When I use a word,” Humpty Dumpty said, in rather a scornful tone, “it means just what I choose it to mean—neither more nor less.”
— Humpty Dumpty, in Lewis Carroll's Through the Looking-Glass
Determinism. This refers for the ability to produce the same output from the same input (assuming the same model, software, drivers, and hardware). In practice, this refers to whether the model produces the same next-token prediction scores (logits) given the same input. It’s about reproducibility of the system—not about being right or creative.
Truth. Whether a claim matches the real world. It's useful to consider this in two categories: objective and subjective truth.
Objective Truth or Factuality: For verifiable facts like, "What is the boiling point of water?" the model's output is "true" if it aligns with established, real-world knowledge. Its ability to produce objective truth is driven by the accuracy of its training and in-context data, and its own capability to use this data correctly.
Subjective Truth with Representativeness: For matters of opinion, interpretation, and values like, "Is abstract art meaningful?" the model essentially synthesizes the vast spectrum of human perspectives from its training data to generate a plausible or representative viewpoint. This means the default pathways in the model reflect a majority or dominant cultural opinion, but specific directions in the prompt can steer the model to reflect a specific viewpoint.
Creativity. From a user's perspective, creativity in an LLM is the model's ability to produce text that feels novel, interesting, and non-obvious, while still being coherent and relevant to the prompt. It's the capacity to generate a new poem or a unique marketing slogan. This user experience of creativity is technically derived from intentional and controlled randomness in the token selection process (covered later in the article).
Hallucinations. A hallucination is said to occur when an LLM generates text that is plausible and confident, but is factually incorrect. At its core, it is a failure of the model to distinguish between its internal, statistical representation of the real world (facts) and plausible-sounding fiction. Because the model's primary goal is to generate a fluent sequence of words, it can sometimes blend the style of a factual statement with the content of a fictional one.
Active research is taking place to eliminate or reduce hallucinations: The fact that AI can be confidently wrong is one of the biggest hurdles to its reliable use. And of course there are major ongoing efforts focused on building in models the crucial ability of knowing when they don't know something. Here’s a recent post from OpenAI, and another very recent one from Google.
Common Misconceptions
Misconception #1: Deterministic responses are truthful responses.
Reality: Determinism guarantees repeatability, not truthfulness. In the context of LLMs, determinism can guarantee the same next-token probability distribution, but that doesn’t make it more true.
Example: To the question “What is the capital of Australia?,” the LLM can answer every time with “Sydney” but that doesn’t make it right.
Why it matters: Deterministic outputs lead to consistent model behavior, and help measurement and testing; they don’t guarantee factuality.
Misconception #2: Non-determinism is what leads to Hallucinations
Reality: Hallucinations are the result of the model's inability to distinguish between when it knows something and when it doesn’t know something. A model can produce a fabricated "fact" via a perfectly deterministic path. Making the output deterministic doesn't make it true.
Example: To the question “Who won the gold in 100m sprint in 2028 Oympics?,” the LLM can deterministically answer every-time with “Dean Jones” but that doesn’t mean it has basis in reality. Even if the event hasn’t happened yet, the model may fabricate a plausible name.
Misconception #3: Non-determinism is Necessary for Creativity
Reality: Creativity in LLMs comes from intentional randomness introduced through decoding strategies like temperature and top-p sampling. Non-determinism can also arise from unintentional system variability (e.g., batching effects), which produces random drift without creative intent.
Example: A prompt run twice produces slightly different outputs due to batch variance, but both continuations are bland and repetitive. This is non-deterministic but not creative.
Why it matters: Conflating the two leads to frustration; true creativity requires deliberately tuning the right knobs (like temperature), not just accepting random system quirks.
Misconception #4: Creativity leads to falsehoods
Reality: Creativity is the ability to generate diverse and novel—but still plausible—continuations. A model can be creative while remaining entirely factual, or it can be creative in a fictional context. The output's truthfulness is a separate, unrelated dimension.
Example: Asking an LLM to "explain photosynthesis in the style of a pirate" can produce a creative and engaging answer that is still factually correct.
Why it matters: Dismissing all creative outputs as false means missing out on the LLM's power to brainstorm, rephrase, and explain concepts in more engaging ways.
A Few Common Technical Misconceptions
Technical Misconception #1: Temperature=0 makes answers factual.
Reality: Setting temperature to zero path removes decoding policy randomness. It doesn’t verify facts.
Example: The model repeats an outdated statistic confidently; turning down temperature only makes the mistake consistent.
Why it matters: Claims that “lower temperature improves accuracy” are over-reading a stability knob.
Technical Misconception #2: Setting a seed makes everything deterministic.
Reality: The seed is only used in the Token Sampling step. It ensures that the random choice from the final candidate pool is repeatable. It has no effect whatsoever on the decoding policy introduced randomness or unintentional variability that can occur back in the inference phase, which can change the logits themselves and lead to a different output even with the same seed.
Example. Two runs with the same seed diverge because one was processed in a larger batch, nudging the logits.
Why it matters. “Seeded for determinism” means “sampling is fixed,” not “the entire stack is invariant.”
Technical Misconception #3: Batch-size nondeterminism is just floating-point voodoo.
Reality. Floating-point quirks are part of it, but the another root cause is order of operations changing with batch shape or scheduling.
Example. The same prompt answered alone vs. grouped with seven others takes a slightly different compute path causing tiny logit shifts flip a softmax later.
Why it matters. When you see “same prompt, different output,” ask whether the inference setup changed. The concept to look for is batch invariance. Thinking Machine’s paper proposes a way to address this.
Technical Misconception #4: “Deterministic” means identical across all machines and versions.
Reality. Most real guarantees are scoped per same weights, tokenizer, libraries, drivers, and GPU family. Change any of those and tiny numeric changes can appear.
Example. Bit-for-bit identical on an A100/CUDA stack does not imply bit-for-bit identical on an H100/CUDA.
Why it matters. When reading papers or provider claims, look for the determinism envelope to understand what exactly the promise covers.
Anatomy of Token Generation: A Step-by-Step Guide
At its core, an LLM is a sophisticated prediction engine. Its main job is to answer the question: "Given this sequence of words (tokens), what word (token) should come next?" The diagram below illustrates this process focusing on the token selection, which we can break down into seven key steps.
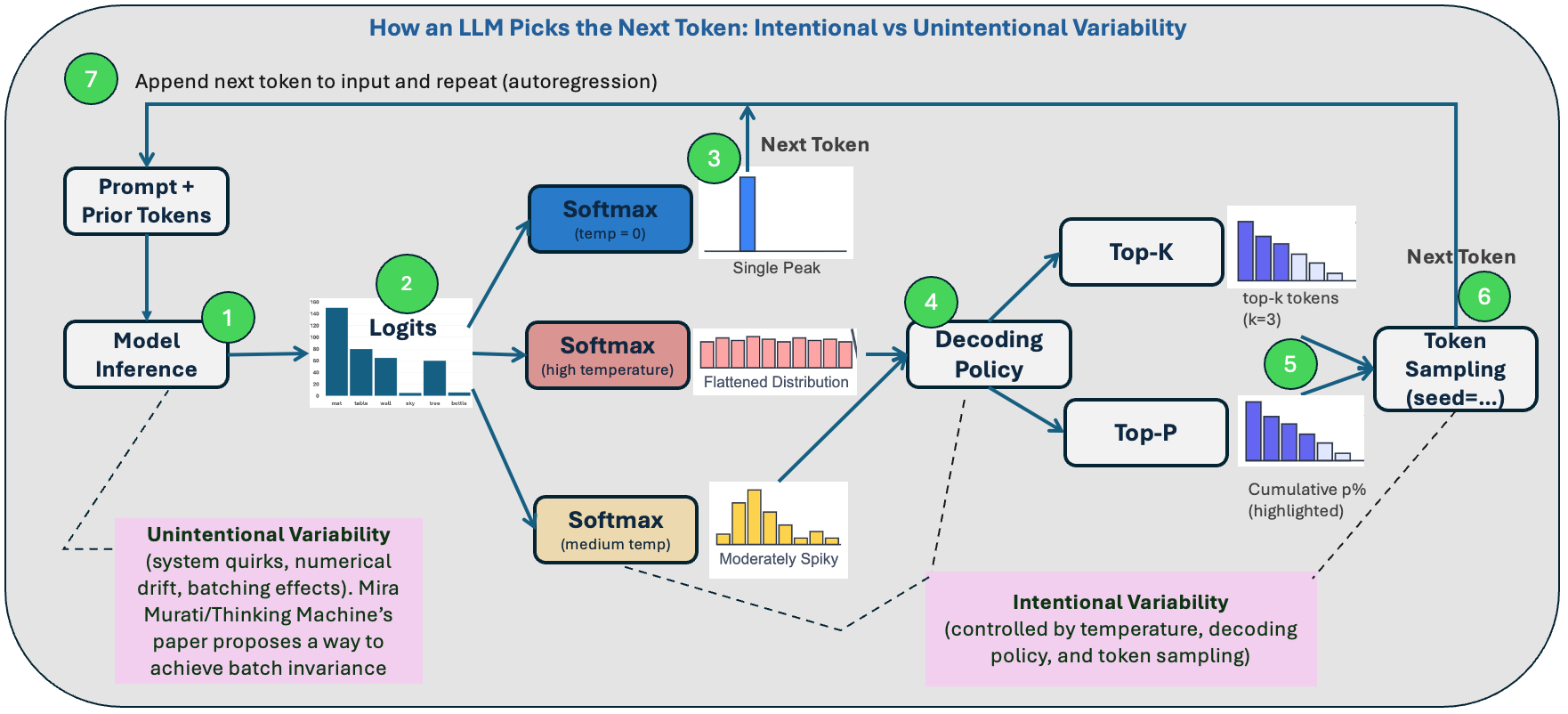
The Model Generates Raw Scores (Logits). The model processes the prompt + prior tokens to produce logits (raw, unnormalized scores) for every token in the model’s vocabulary. This is where unintentional variability resulting from the numerical drift from batching, kernel order, or hardware tactics can creep in.
Scores are Converted to Probabilities (Softmax). The raw logits are then passed through a Softmax function. This is a crucial mathematical step that transforms the long list of scores into a proper probability distribution, where the probabilities of all possible tokens add up to 1. This is also where the most important control for creativity, temperature, is applied. As the diagram shows, temperature controls the shape of the probability distribution:
High Temperature: Flattens the distribution. This boosts the probability of less likely tokens, making the model's output more diverse, creative, and sometimes surprising.
Medium Temperature: Creates a "spiky" distribution that still strongly favors the most probable tokens but allows for some variation. This is often a good balance between creativity and coherence.
Temperature = 0: This is a special case. It creates a distribution with a single peak, giving a 100% probability to the single most likely token and a 0% probability to everything else.
The Greedy Decoding Path. When temperature=0, one token gets the maximum probability of 1, and the model selects it directly. This is called greedy decoding. It's the most direct and predictable path, completely bypassing the need for any further decoding or sampling.
Decoding policy. If you want diversity, you deliberately introduce randomness by using a decoding policy to create the final candidate pool of tokens you’ll sample from.
Creating the candidate pool of tokens. For any temperature above zero, the model has a distribution of options. The two most common methods are:
Top-K: A simple rule that tells the model to only consider the 'k' tokens with the highest probabilities.
Top-P: A more dynamic rule that tells the model to consider the smallest group of top tokens whose probabilities add up to at least a certain percentage 'p'.
Token Sampling (seed=…). From this final, filtered group, one token is chosen through a weighted random selection. A token with a higher probability has a higher chance of being picked, but other tokens may be selected as well with their corresponding probability. This is the step where a seed is used. By providing the same seed, you ensure that the same pseudo-random choice made at this specific step is the same every time. This makes the sampling process repeatable.
The loop repeats (autoregression). The chosen token (from greedy or sampling) is appended to the input and the loop repeats. The entire process, from Step 1 to Step 6, then repeats to generate the token that comes after it. This cyclical, one-word-at-a-time process is called autoregression.
Two purple callouts in the diagram reinforce the distinction:
Unintentional variability sits within model inference
Intentional randomness sits with your decoding policy—what you dial to get creativity or stability.
Conclusion: Mastery Begins with Clarity
The language we use to describe LLMs is a minefield of misunderstood concepts, where technical terms are often used as proxies for desired outcomes. As we've seen, determinism is not a synonym for truth, creativity does not have to imply hallucinations, and random token selection doesn’t negate determinism. Instead, these are distinct dimensions of a model's behavior, each controlled by different mechanisms.
The path to building and deploying AI responsibly doesn't just depend on bigger models; it depends on the clarity of our thinking.