
LLMs and Human Brains
Eight analogies exploring how they each learn

«Disclaimer: these analogies, like all analogies, aren’t perfect. There’s a big difference between humans and LLMs - we operate in a very messy physical world; LLMs operate in a digital world with less messiness but also don’t have our rich sensory experience. A full book, not a short article like this, would be needed to list out all the commonalities, exceptions, and nuances. Finally, to reach the maximum audience I’ve eschewed using technical jargon and details as much as possible. »
LLMs are created from human knowledge, culture, and values expressed in text. So, it’s not a surprise when they act and behave like humans. At the same time, they are different from us in many important ways given that they are created using a completely different method compared to evolution (think of birds vs airplane).
In this article, I’ll develop this idea more fully, comparing some key LLM concepts to their human analogues. For those that aren’t familiar with the technical details of how LLMs are built and work this comparison should give a better and intuitive feel about LLMs. Even those that are intimately familiar with LLMs’ training and inner workings may gain some additional insights. Or perhaps more importantly, they can point out in the comments section where I got things horribly wrong :)
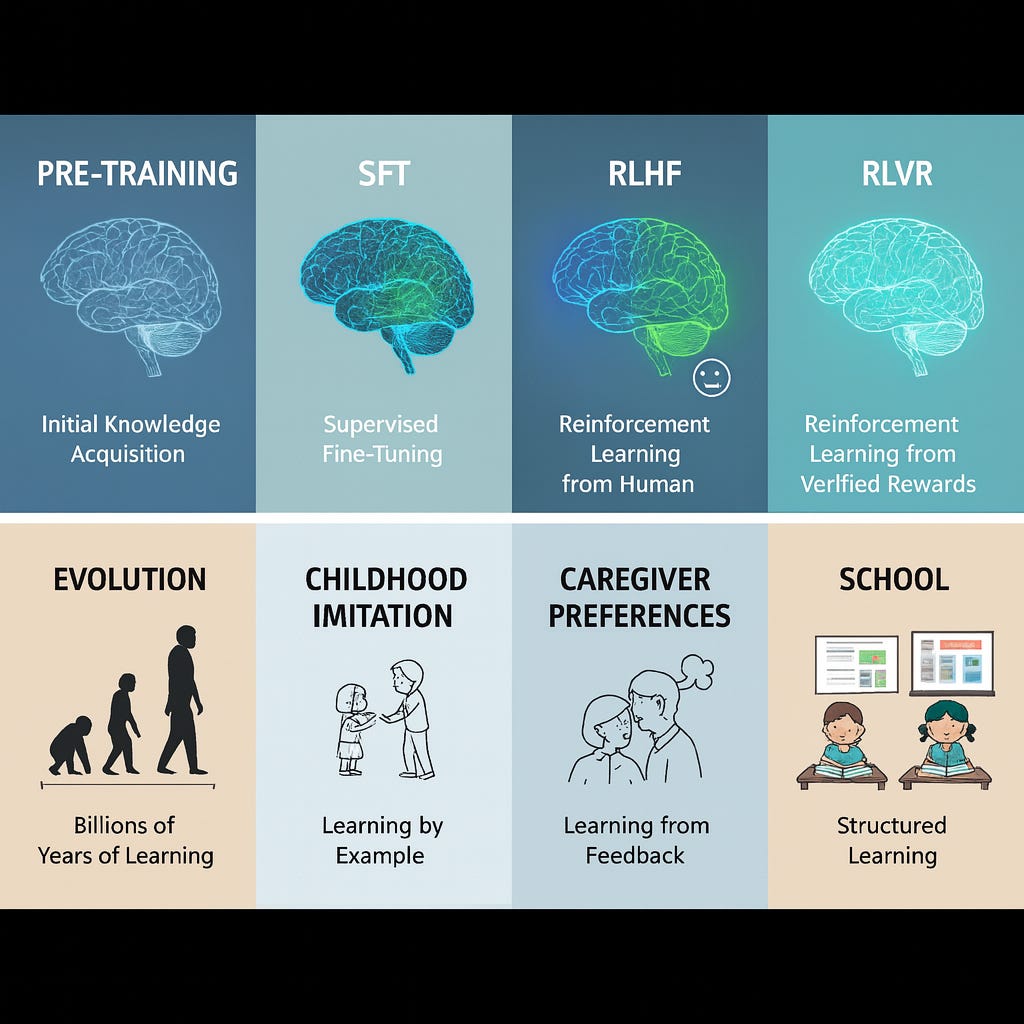
Evolution vs. Pre-training
Evolution spent billions of years ‘searching’ for brain designs and encoding the instructions in our DNA, governing not only our brains but our entire bodies. A newborn baby’s brain doesn’t come with pre-built factual knowledge, but it has innate capabilities to learn from and operate in its environment. For example, it will soon be able to grasp things by hand and learn the particular language(s) it’s exposed to.
In comparison, LLMs can be created in a few weeks’ training on trillions of words of text with the objective of guessing the next token (word) given a sequence of tokens (words). The resulting neural network comes with vast pre-built knowledge and a limited world model. It doesn’t, however, know quite how to engage in conversations, be helpful, reason through problems or how to use tools.Childhood immersion/imitation learning vs. Supervised Fine-Tuning (SFT)
Toddlers learn how to communicate through immersion and imitation. LLMs learn how to converse after being trained with thousands human-generated examples of prompts (“How are you today?”) and responses (“I am fine. Thank you. How are you?”). Using these examples, SFT teaches LLMs the basic structure of conversations and task following behavior.
Parental guidance & social conditioning vs. Reinforcement Learning through Human Feedback (RLHF)
Feedback from parents and the broader social circle teaches children to behave in ways the children find rewarding, thus sculpting their communication and behavior. RLHF fine-tunes an already pre-trained, instruction-following LLM by incorporating human preferences as a reward signal. The model learns to generate responses that humans prefer. For example, responses that are polite, helpful, and honest.
School or Structured Learning vs. Reinforcement Learning with Verifiable Rewards (RLVR)
IMO, this is a tricky analogy to make, but I’ll give it a go. Humans learn how to apply logic, solve math problems and write programs through structured teaching, and are tested and corrected with objective tests. To achieve a similar outcome in the case of LLMs, we take problems with verifiable answers and feed them to LLM - we reward them when they produce correct answers. Note that we don’t really tell them how to solve problem the way we teach humans. We just give them the problem and just reward them when they get it right, and somehow LLMs learn how to allocate more effort and ‘reason’ to solve the problems.
Lifelong learning and long term memory vs. In-context learning (ICL) & short term memory
Humans continue to learn throughout their lives. New experiences, skills, and knowledge gained are compressed and stored into their long term memory (sleep perhaps plays a role here), enabling later recall and reuse. Once training is complete, LLMs’ knowledge and skills are frozen when they’re released to production. They have a very limited amount of working memory (called the context), and can learn new skills if we provide them with a description and/or a few examples within that context. This is called in-context learning, and it’s lost when the short term memory overflows or when a new context is created.
Rules and Laws vs. System Prompts
Humans are governed by rules and laws that they are meant to follow. LLMs are given a similar set of guidelines and rules via system prompts (which reside at the beginning LLM’s working memory/context). Of course, just like humans, LLMs may or may not follow those rules :)
Reference materials vs. Placing information in working memory
Humans aren’t expected to memorize every fact. They can look them up in books or online. A prompt to an LLM can also embed any additional information that the LLM can use to better answer the prompt.
Human Tool use vs. LLM Tool use
Humans have an innate ability to use tools in general, and during their lives they learn how to use specific tools through practice and demonstration. LLMs see code, APIs, and tool-related text during pre-training, which give them a rough sense of what “tool use” is. They are then given specific tool use examples during supervised fine-tuning and are rewarded for correct tool use during the reinforcement learning (RLHF/RLVR) phases. As mentioned above, LLMs can also learn how to use specific tools in-context when provided with a description and/or a few examples. This capability lasts while that context is active and is not carried forward into future sessions.
In conclusion, the comparison isn’t perfect, but it reveals to us a little bit about how the two intelligences are similar and different. We are the result of a billion years of evolution, while LLMs are imperfect (or perhaps simply different) digital reflections of ourselves.
Couldn't agree more. Your ideas on LLMs and the brain always sparks so much wonder. So insightful!