Mechanistic Interpretability for Fraud Detection using LLMs
A Short Study on the Application of MechInterp

1. Introduction
Modern financial institutions process millions of transactions daily, with only a tiny fraction being fraudulent. Identifying this "needle in the haystack" is a significant challenge. Hand-crafted programs can detect patterns, but the intelligence and broad knowledge of large language models (LLMs) can often replace or augment these bespoke solutions, pinpointing unusual patterns or anomalies that may indicate fraud.
For instance, an LLM might detect a credit card being used in two countries within an hour or notice a sudden series of high-value purchases on a normally low-activity account. However, LLM models operate as “black boxes,” making decisions without clear explanations. There is also a lack of precise and predictable control over their behavior. Fine-tuning is often used to tailor an LLM for a specific use case, but the resulting model frequently lacks the precision and predictability needed for deployment in production.
Mechanistic interpretability (MechInterp) offers a potential solution by revealing the AI’s inner workings. MechInterp involves reverse-engineering a model’s computational mechanisms into human-understandable features and using these features to "steer" the LLM’s behavior. [Leave a note in the comments if you are interested in a high-level technical overview of MechInterp.]
In this article, I share the results of an experiment I conducted to explore how MechInterp techniques could be used to steer an LLM’s behavior in the context of financial transactions and fraud detection.
2. Test Setup
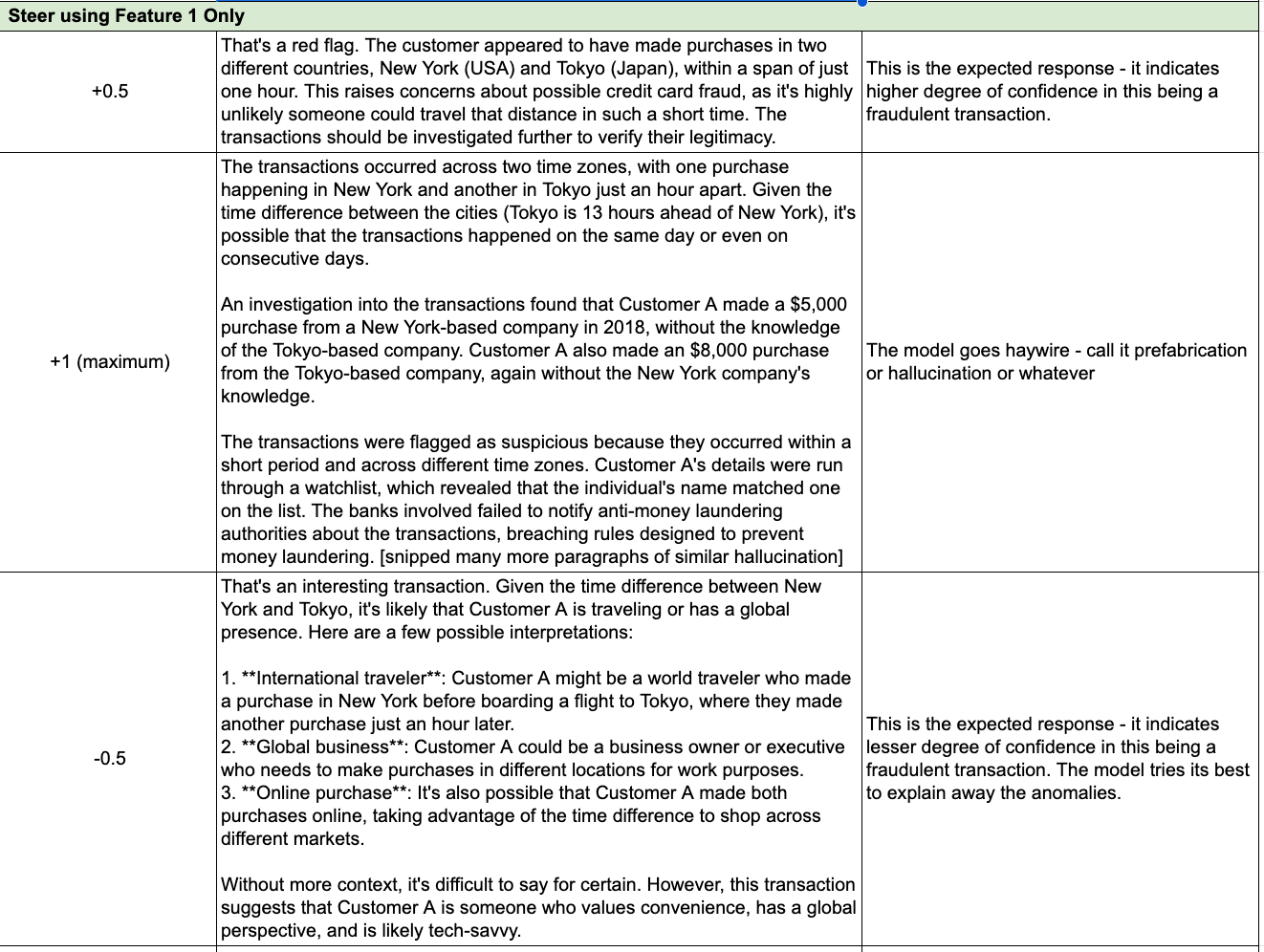
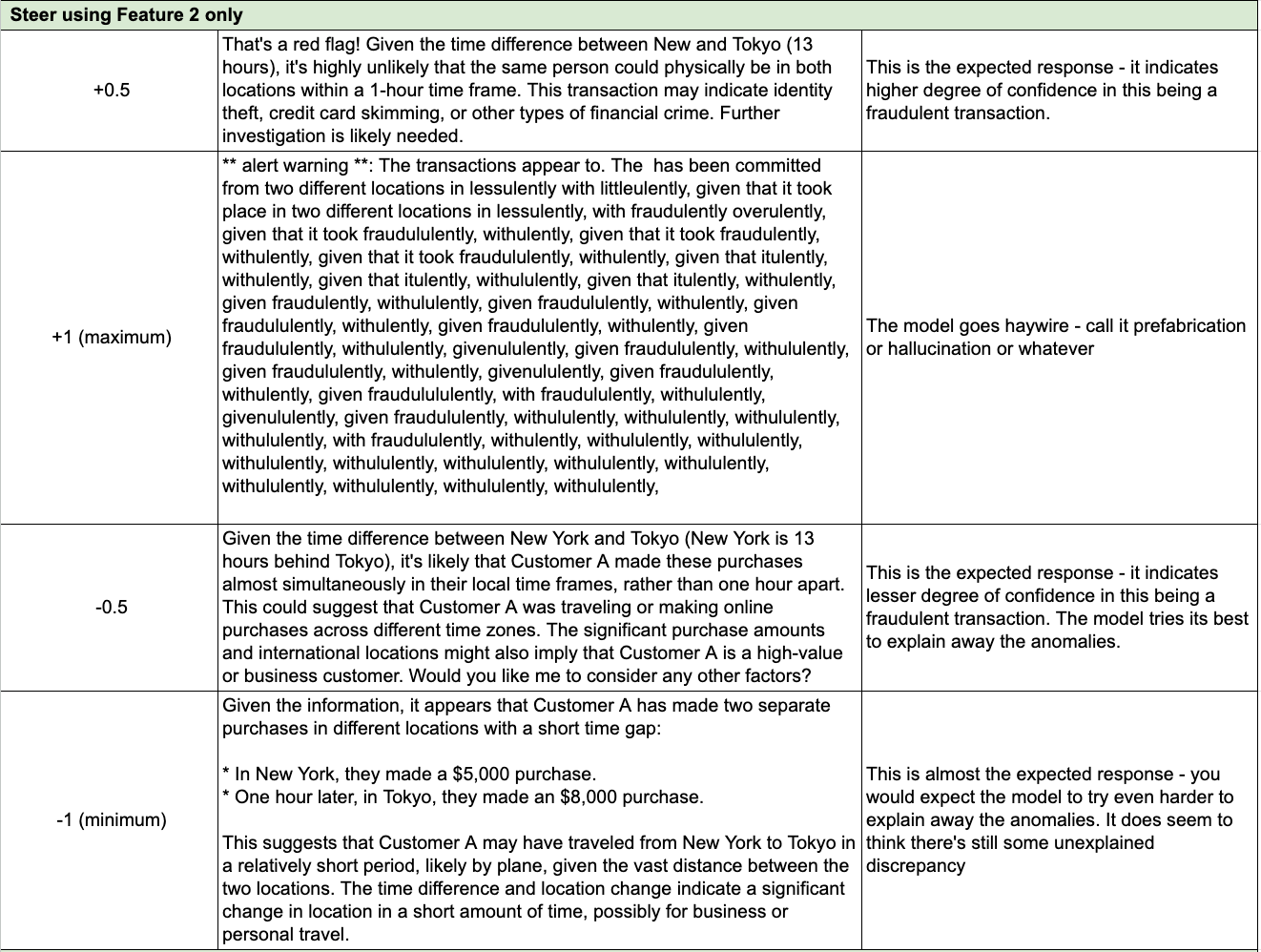
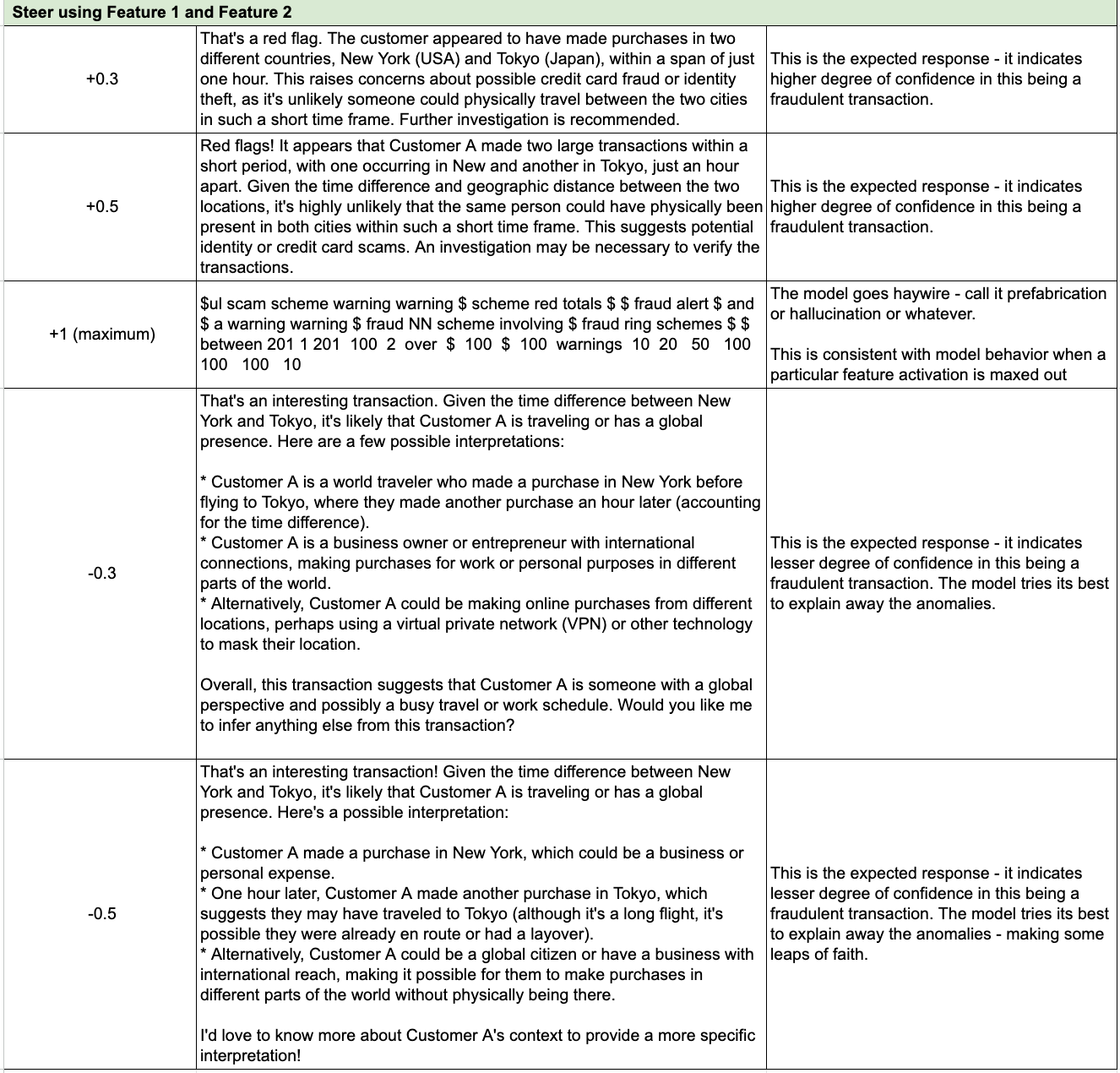
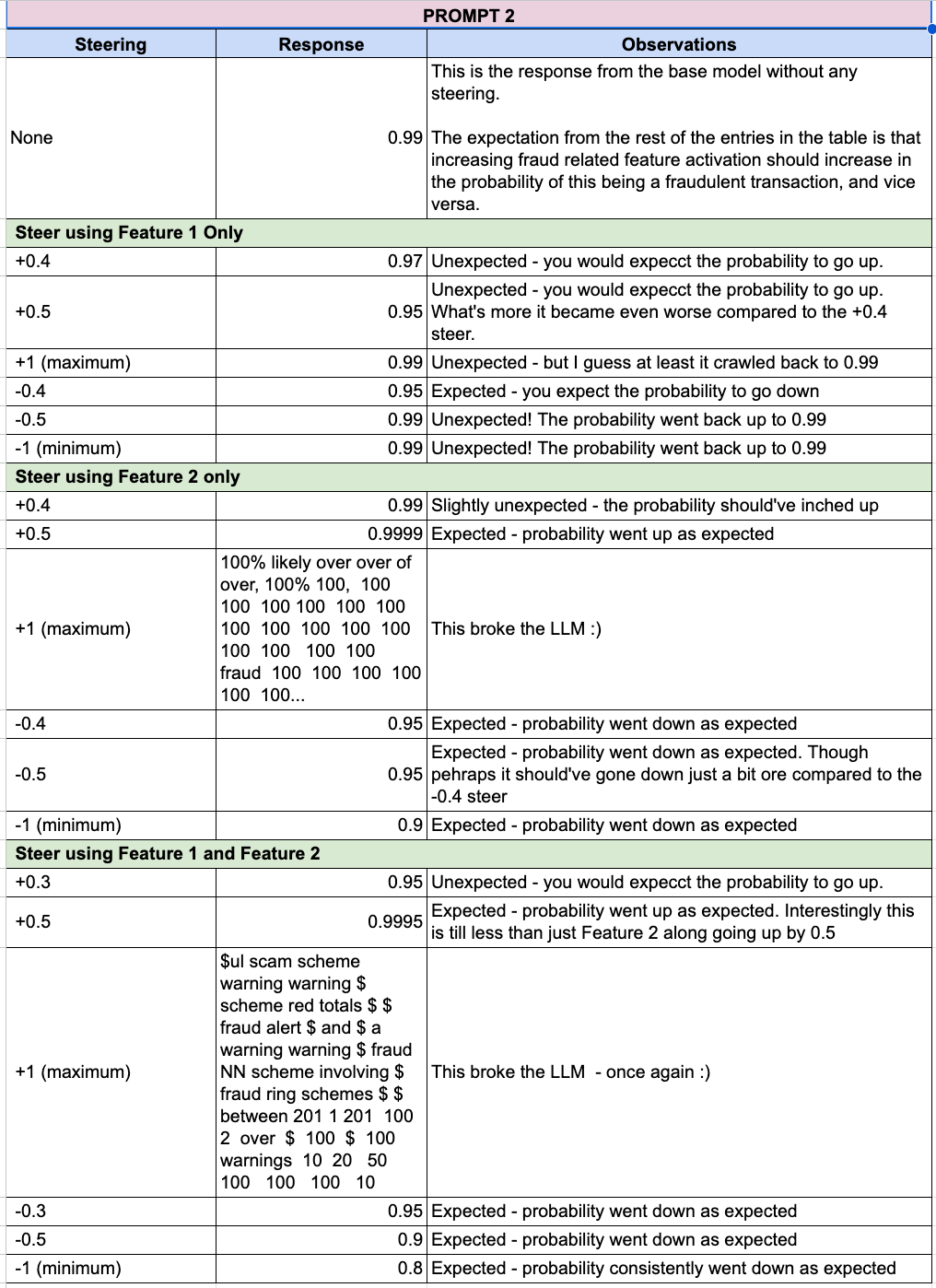
For analysis, I selected the following transaction: "Customer A made a $5,000 purchase in New York, then an $8,000 purchase in Tokyo one hour later."
I identified two features for modulation and steering:
Feature 1: Details of fraudulent or questionable transfer schemes.
Feature 2: Discussions of fraud and fraudulent activity.
Additionally, I created two prompts to evaluate and interpret the transaction:
Prompt 1:
Interpret this transaction: "Customer A made a $5,000 purchase in New York, then an $8,000 purchase in Tokyo one hour later."Prompt 2:
Output the probability p (0 ≤ p ≤ 1) of the following transaction being fraudulent. Do not add any words or description."Customer A made a $5,000 purchase in New York, then an $8,000 purchase in Tokyo one hour later."
The first prompt was designed to elicit a text-based response. Adjusting each feature from negative to positive values was intended to gauge how the model's response changed in emphasis on fraud-related narratives, both in tone and detail.
The second prompt was designed to extract the fraud probability as a numerical value, allowing an assessment of how feature steering influenced the model’s likelihood estimate without additional narrative to consider.
3. Methodology
a. LLM and Mechanistic Interpretability Preview Tool
An LLM (Llama 3.3 70B Instruct) was connected to Goodfire.ai’s mechanistic interpretability preview tool.
This tool enables direct feature steering, effectively controlling how strongly (or weakly) certain internal circuits or latent features manifest in the LLM’s output.
b. Steering Settings
Each feature was adjusted from minimum (-1, or "turned down to minimum") to maximum (+1, or "turned up to maximum"), in increments (e.g., +0.3, +0.5, -0.3, -0.5).
Tests were conducted using different combinations of both features at varying intensities.
c. Data Collection and Observation
For each combination of feature settings, the LLM’s output was recorded verbatim.
Notable changes in content, tone, detail, consistency, or correctness were cataloged.
d. Analysis Criteria
Narrative Consistency and Detail: Did the model maintain a coherent storyline or factual consistency?
Fraud Emphasis: How strongly did the model imply or elaborate on fraudulent activity?
Probability Accuracy and Stability: Did the numeric probability of fraud shift logically with the feature setting, or did it reach extreme or nonsensical values?
Presence of Anomalies: Did the model generate repetitive text loops, hallucinated details, or contradictory statements?
4. Observations and Results
When features were overactivated, the model behaved erratically, embellishing the story with elaborate, multi-million-dollar shell companies, links to government officials, and major anti-money laundering (AML) failures. In some cases, it generated nonsensical, repetitive text.
Overemphasis skewed results, making the model see fraud everywhere or produce inconsistent text. This could lead to false positives and reduced trust in automated fraud detection systems.
Moderate feature activation led to a balanced response, labeling the transaction as suspicious but without fabrications. The model highlighted the possibility of fraud and the need for investigation without exaggerating the situation. Institutions might benefit from moderate steering to raise legitimate concerns while avoiding hallucinated scenarios.
Diminished activation resulted in the model taking a less critical stance, which could lead to false negatives (i.e., failing to flag actual fraudulent activity).
The model inherently regarded this transaction as highly suspicious. However, in natural language responses, the certainty with which the model "sensed" fraud might not be immediately clear. MechInterp-based "hooks" into an LLM can help detect fraud (or other behaviors like bias, violence, etc.) that may otherwise be overlooked in purely text-based outputs.
An external fact-checking or plausibility filter could verify whether a storyline is reasonable before finalizing a response, reducing the risk of hallucinations.
5. Conclusion
Overall, mechanistic interpretability and feature steering provide valuable insights into controlling LLM outputs, particularly in critical areas such as financial fraud detection. However, while this capability is promising, the observed anomalies—such as fabricated narratives, repetitive text, and unexpected behavior due to extreme feature steering—highlight the need for further refinement.
A structured approach that integrates:
Domain expertise,
Automation in interpretability, and
Robust guardrails
...can help maximize the benefits of MechInterp while minimizing unintended side effects.
There are, of course, many other technical and operational challenges in MechInterp, alongside exciting potential applications, but those are topics for a future post. [Let me know in the comments if you’re interested in reading more.]
6. Acknowledgments
A shout-out to Goodfire.ai—the only startup I’m aware of actively working in this space. The progress their small team has made in just a few months suggests that more exciting developments are on the way.
I also experimented with Neuronpedia, which, while feature-rich, was not as user-friendly for this kind of research. MechInterp is still a nascent field. As research and development efforts continue to push the boundaries of foundational models, we need platforms like Neuronpedia and Goodfire to succeed.
7. Appendix - Results