
The Holy Grail of AI in Trading: Can We Finally Forecast the Markets?
Challenges, past attempts, and a blueprint for building a multimodal fusion model for financial prediction.

Preamble
Inspired by Asimov’s Hari Seldon and psychohistory, I’ve carried around an idea for a novel for years. The novel’s protagonist, a brilliant but flawed mathematician, finds the holy grail of applied AI in trading: an app that forecasts financial markets with uncanny precision. The app would take in torrents of data in real-time and would make probabilistic predictions minutes, hours, and days into the future. His challenge, of course, is to keep it a secret while profiting from it because making it public would stop it from working.
I never wrote that novel. Mostly because life got in the way, but I never stopped thinking about how to create that market forecaster. All this time a market forecasting app that can work with the accuracy of a weather forecasting app seemed more like a piece of science fiction than an engineering project. With all the recent advances in deep learning, however, creating such an app feels a lot more feasible now.
In this article, I’ll talk about why market forecasting is such a hard problem to solve, look at some of the notable attempts at solving it, and propose an architectural vision for a model that might finally get us there.
The Herculean Challenges of Market Prediction
At first glance, market prediction might not look daunting for the uninitiated. After all, if we can create planet-scale weather forecasters and LLMs that write poems, produce code, and even win gold medals at the International Math Olympiad, surely building a narrower, special-purpose system ought to be easier? A market forecaster doesn’t need to understand Tolstoy and TikTok memes (or does it?); it only needs to make sense of prices and events to make decent probabilistic predictions of future prices.
But forecasting markets isn't like predicting the weather, where the underlying physics is mostly understood. Neither is it like creating a general purpose large language model. Markets are a different beast entirely, plagued by a few fundamental problems.
The first major hurdle is the problem of non-stationarity. In simple terms, a stationary process is one whose statistical properties (e.g., mean, variance and correlations) don't change over time. And financial markets are maddeningly non-stationary. The rules of the game are constantly shifting. A pattern that worked beautifully for a year can suddenly vanish because of a viral outbreak, a regulatory change, the outbreak of a war, a technological disruption, or a shift in the geo-political environment. This is why simple models like ARIMA (Autoregressive Integrated Moving Average), which rely on past patterns repeating, often fail spectacularly. Any successful solution, therefore needs a sophisticated, adaptive world model that truly understands and adapts to the underlying regimes and dynamics.
The second major hurdle is data:
Building a true world model requires an unimaginable amount of diverse, high-quality, and perfectly time-stamped data. We need everything: real-time news feeds, social media feeds from platforms like X, geopolitical event data, central bank announcements, earnings call transcripts, corporate actions, earnings reports, weather forecasts, satellite imagery of oil tankers, and of course, all the financial time-series data including stock prices, trading volumes, FX rates, interest rates, and bond yields.
Also, this data is multimodal, coming in the form of free text, structured data and maybe even images and video. A successful model must be able to fuse these different streams together to form a holistic picture.
Acquiring the data is also extremely challenging as much of the high-quality data is fragmented and locked behind expensive paywalls.
This also requires careful engineering to avoid data leakage, ensuring that our model isn't accidentally "seeing" information from the future during training, which would make it look deceptively brilliant in backtesting but useless in the real world.
Of course, the world of finance has adversarial players, and data of all varieties and especially those from social platforms can be poisoned. Defensive mechanisms need to be in place to identify and remove such data. Perhaps a sophisticated model would learn to ignore such data just as a expert human would!
Finally, there’s the problem of reflexivity. If a forecasting engine gets widely adopted, the very action of trading off its predictions can change market behavior, weakening its predictive power. This might seem academic, but it can disincentivize firms from investing heavily in building such models as keeping them proprietary can be very difficult (their employees who know how to build the model can be poached by competition).
A Brief History of Market Forecasting Attempts
Early attempts relied on statistical methods like ARIMA and GARCH. While foundational for time-series analysis, they don’t take into account all the non-time-series information available, and are ill-suited for the complex, multivariate, and ever-changing nature of financial markets. The machine learning revolution brought more powerful techniques, but many early models were still limited, often focusing on a narrow set of technical indicators.
The success of deep learning and transformers attracted researchers’ attention, and one of the first notable efforts was FinBERT, a model based on Google's BERT architecture but fine-tuned on a large corpus of financial text to understand the sentiment of financial news. However, FinBERT is quite dated at this point, and is not a forecasting engine. BloombergGPT made headlines in 2023 as a massive language model trained from scratch on Bloomberg's vast, proprietary dataset of financial information spanning decades. Like FinBERT, its primary goal wasn't to be an end-to-end forecasting system. It's a financial knowledge base, not a predictive machine that integrates real-time data to make predictions.
Since 2024, there’s been a new wave of research projects that are moving closer to what I think is the right approach. With efforts like MSMF (Multi-Scale Multi-Modal Fusion) researchers have started moving in the right direction, attempting to fuse textual data like news with price data. Similarly, agent-based simulators like FinArena aimed to create realistic environments to test trading strategies. While these are important steps in the right direction, they are academic exercises trained on limited public data and haven't yet been deployed at the scale or with the breadth of data needed to build a true market-spanning forecasting engine.
The Proposed Solution: A Multimodal Fusion based Market Forecaster
So, here’s my vision: a multimodal fusion forecasting architecture that ingests all kinds and modalities of financial data simultaneously to build a unified understanding of market’s state, dynamics and trajectory to provide probabilistic forecasts across varying time horizons.



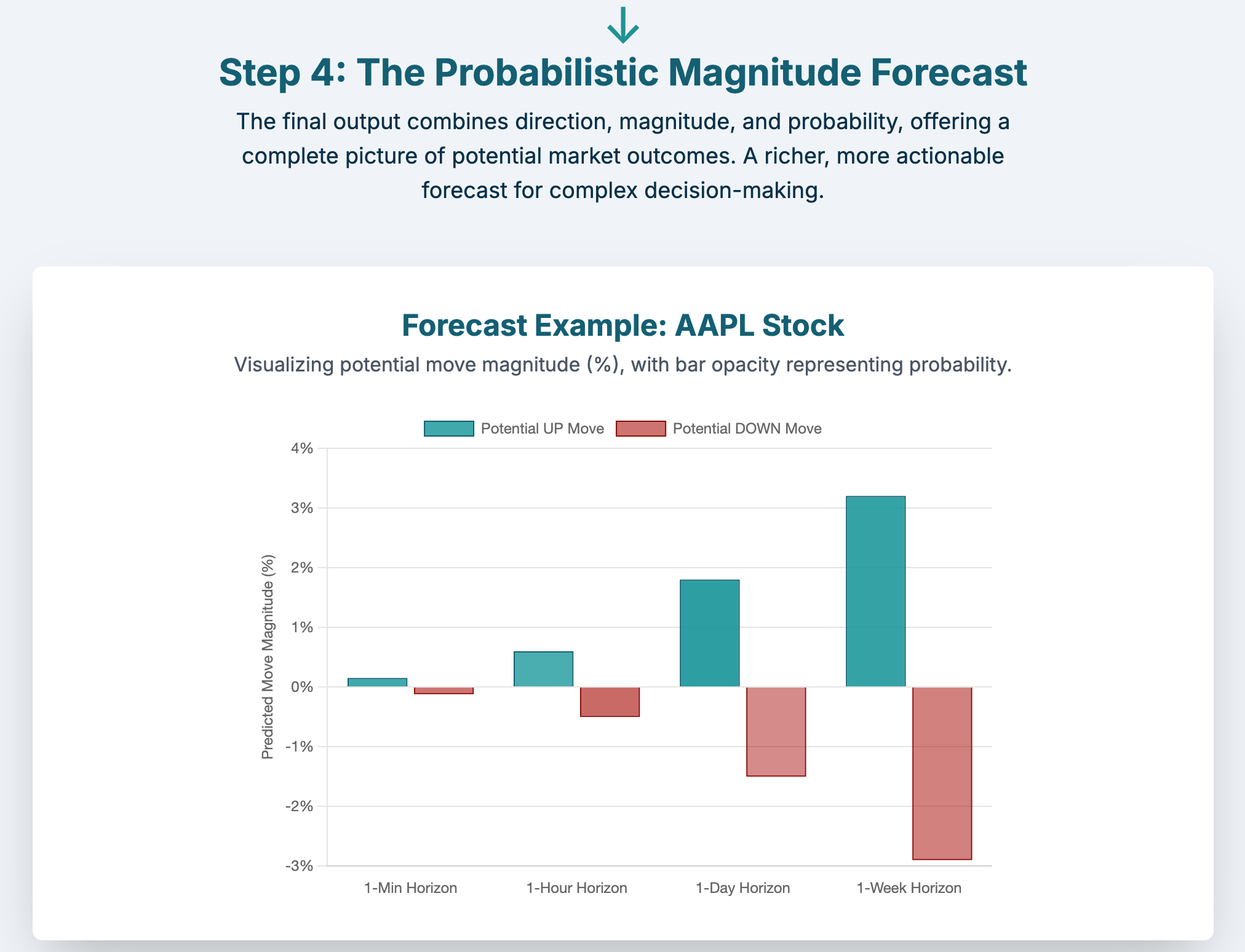

Conclusion
I'm confident that a model built on this architecture would outperform a human analyst or a specialized, single-purpose algorithm. It would make decisions based on a more complete and holistically processed set of information than anything that has come before. I also admit that it’s extremely difficult and expensive to build with massive data, compute and engineering demands, and could potentially face regulatory obstacles. Then there’s the challenge of reflexivity: models that forecast may, if broadly deployed, invalidate themselves.
With so much of the AI world currently focused on the grand challenge of Artificial General/Super Intelligence (AGI/ASI), it's unlikely that major labs like Google or OpenAI would pivot to such a specialized, high-risk financial project. This leaves the field open to a few specific players. A data behemoth like Bloomberg, which sits on a large proprietary dataset, is one obvious candidate. Another is a well-funded, AI-native quantitative hedge fund like High Flyer (which owns DeepSeek). They might have the resources, the incentive, and the right kind of DNA.
Smaller, more constrained versions could probably be built today to prove the concept. One could start by focusing on a single asset class, like FX or a specific sector of the stock market. But ultimately, I believe a comprehensive, all-encompassing fusion model is the only path to obtain the holy grail of market forecasting.
Psychohistory may still be science fiction, but with multimodal fusion, a market forecaster is closer to become real.
Great read! Market timing is so challenging because, unlike physics, it depends on human behavior.
As Newton said, "I can calculate the motion of heavenly bodies, but not the madness of people."
And as Feynman joked, "Imagine how much harder physics would be if electrons had feelings!"