
Why Is It So Hard to Get AI Agents to Work in the Enterprise?
Hint: it’s not just picking the wrong business case, bad data, or MCP or any other framework.

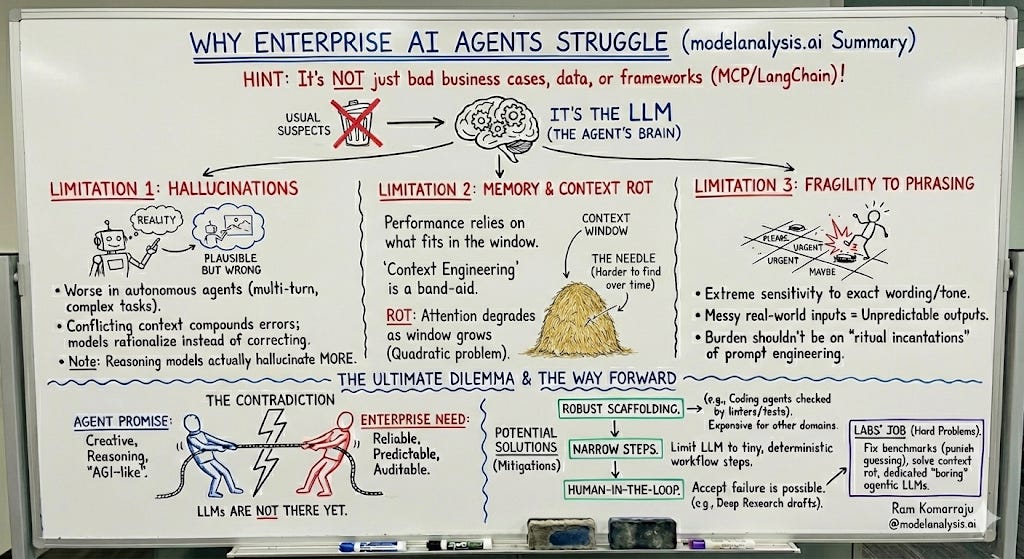
The year 2025 was supposed to be the “Year of the Agent,” but every week seems to bring another study from a major university or a leading consulting firm explaining why agent deployment in the enterprise has been far slower than expected. Many resort to platitudes like “put the business case front and center,” or “focus on getting the data right,” as if not following those tenets is all that’s holding agents back. Others blame MCP, LangChain, or some other framework. Yet others put the blame on software engineers for not knowing how to build agents properly.
In other words, many people are prone to blame anything but the LLM, the brain of the agent. In the rest of this article, I will share the current limitations of LLMs that make it extremely hard to implement agents in the enterprise. I’ll then cover potential ways in which these limitations can be addressed.
«Note that I don’t include “lack of continual learning” as a major limitation preventing us from deploying AI agents successfully in the enterprise. I’m assuming that addressing the below limitations is sufficient for this purpose, but might have to think more deeply about lack of continual learning at some point.»
Hallucinations
A key limitation driving even state-of-the-art models to be unreliable agents is hallucination, whereby a model generates plausible but wrong responses (i.e., responses inconsistent with either the input context, the model’s previous outputs, or the knowledge contained in its training data).”
Models have always suffered from hallucinations, but the impact is far greater when they are employed as autonomous agents:
There’s simply a lot more opportunity for something to go wrong with all the stuff that happens while an agent is executing a task: reasoning/planning, tool calling, long-term memory/context, and multi-turn execution. Models tend to hallucinate more when context is embedded with incorrect or conflicting information (which is common and often unavoidable in real-world agent deployments). Where an average human might recognize the incorrect information and choose to ignore it or correct it, a model may instead rationalize it and expand upon it, compounding the error. Once a hallucination makes it into the context window of a model, there is no easy way to identify and remove it.
Model hallucination rates remain far higher than many imagine (ranging anywhere from 3% to 30+%, depending on the benchmark and the type of hallucination being measured). What’s more, reasoning models used in agentic solutions hallucinate more than smaller/’dumber’ models.
Of course, frontier labs are aware of this and are actively working to improve the situation. For example, OpenAI’s recent work proposes shifting the reward structure of benchmarks so that confident errors are penalized and recognizing uncertainty is credited. However, this does not fully solve the core problem, and OpenAI admits that even with improvements, hallucinations would still occur. BTW, I was able to elicit hallucinations from GPT-5.1, released two week ago, using the same techniques that I used in the past.
Limited Memory and Context Rot
An agent’s “memory” is the set of all tokens fed into the context window with every turn. Consequently, an agent’s performance ultimately depends on what fits into that context window. But LLMs have only a limited context window on which the entire agentic solution ends up being built. This has led to the rise of “context engineering” as a profession. A context engineer has to decide what parts of the overall context (e.g., previous user instructions, any supporting data, LLM’s responses, and history of tool calls/responses) to embed within the context window at any time.
Context engineers also have to deal with “context rot.” You see, while a model should in theory be able to pay attention to everything within its context window, that’s rarely the case in practice. An LLM’s performance becomes increasingly unreliable as the context window grows. A user might state a critical fact (the “needle”) at the beginning of a conversation. By the time we reach the 15-minute mark, that critical fact might be buried in a hundred-thousand-token “haystack” of task execution history. Because of context rot, the LLM’s ability to “find” that needle is now lower than it was at the beginning.
Of course, frontier labs are working on increasing the context window length. This is a challenging task because attention computations increase quadratically in relation to the context window length. Any attention optimization techniques to control computational costs and speed need to avoid worsening the context rot problem.
Fragility to prompt phrasing
Another fundamental limitation is the sensitivity of LLMs to the exact phrasing and wording of inputs. Hence the explosion of prompt engineering as a discipline, complete with dozens of guides from Anthropic, OpenAI, and Google, and even “prompt optimizers” that algorithmically search for better prompts. Even if we follow all the guidelines, it is impossible in practice to control everything that makes it into the context window of an LLM, and a single word, a clause, or emotional language can produce dramatically different outputs/behaviors.
In messy real-world environments, inputs often come in varying formats and tones from users, tool/LLM outputs, and logs. Since the LLM can misinterpret any of these uncontrolled inputs (e.g., literally interpret and act on an emotional outburst from the user), the system stays inherently unpredictable. And if inputs truly could be controlled precisely, a deterministic workflow would often suffice without needing an LLM in the first place.
To sum it up, the burden should be on the LLM to behave robustly, not on developers to discover ritual incantations to coax the system into functioning correctly or to hope and pray that the context stays clean.
The Ultimate Dilemma: Deterministic Automation vs Intelligent Agents
Finally, and most importantly, there’s perhaps a central, unsolvable contradiction in current LLM-based agents:
The promise of an agent is that it can reason, plan, and think creatively to solve a complex problem to perform tasks that could only be performed by humans until now.
The requirement of the “enterprise” is reliability, predictability, and auditable outcomes.
And the contradiction between promise and requirement is that LLMs are not reliable, not predictable, and (perhaps) not auditable.
Large enterprises employ thousands, if not hundreds of thousands, of HGIs (human general intelligences). Wherever possible, these organizations continue to replace manual activities with deterministic automation because it’s more reliable and less expensive. LLMs are AGIs (LLMs are artificial, and they have general intelligence, so I’ll call them AGIs, thank you), but even SOTA versions are less reliable, less predictable, and less capable than HGIs across multiple dimensions.
The Way Forward
Build robust scaffolding around LLMs
Coding agents are a great example of this. Of course, the nature of the domain lends itself to such scaffolding. It’s not that LLMs don’t hallucinate or make mistakes when coding. It’s just that there are often verifiable and deterministic ways to check for problems and feed the results back to the LLM to fix them. For example, a coding assistant can send lint results, compiler error/warning messages, runtime logs, unit test failures, etc. to the LLM to fix any issues.
But building such scaffolding for other use cases may not be possible or may prove to be very expensive. The scaffolding approach is where I think we are headed in the short to medium term, because I can’t see the fundamental limitations I mentioned above going away anytime soon, and organizations will find the promise and allure of LLM agents too irresistible not to try this approach.
Limit LLM/agent usage to small/narrow steps within deterministic workflows
The approach requires using LLMs in very specific steps within a larger workflow, controlling tightly what’s fed into their context window, thus increasing their reliability. While this might work, the benefit to be gained in this approach is likely to be very limited, and a traditional, fully deterministic solution would probably be cheaper to implement.
Limit their usage to areas where failure isn’t critical or keep a human in the loop
In this scenario, we recognize the limitations of LLMs and use them in areas where failure isn’t critical. Deep Research is a major example of this approach. The reports generated by deep research implementations contain multiple hallucinations, but the reports are usually meant for some human to use as part of their work rather than publishing them as end products. Of course, having humans in the loop doesn’t mean much if they lack the expertise or the patience to carefully read through the reports, use only what’s correct, and discard or fix inaccurate information.
Improving the LLMs by improving the benchmarks and algorithms
This one is for the model labs, and each of these is a challenging problem with no clear/known solution.
Change LLM training objectives and benchmarks to punish guessing and reward acknowledgment of a lack of knowledge. There’s probably a theoretical limit to how much hallucinations can be reduced, however.
Find ways to increase context window length and fix context rot.
Make the LLM more robust to minor changes/tweaks in prompts. This change will likely make the LLMs seem boring/non-creative as chatbots, and therefore we are likely to have dedicated LLMs trained specifically to be effective in agentic settings.