
The Evolution of Meta's Llama LLMs
Charting the Architectural Progression of its Open Weight Models

«All of this information presented in this article already out there, but seeing it all together might allow one to easily appreciate the evolution of the Llama family of LLMs.»
Meta's Llama family of large language models has rapidly evolved from a research project into a major force in the AI landscape with its open weights license. While it’s no longer the open weight LLM leader (that spot is firmly in the hands of DeepSeek and Qwen’s models), there’s little doubt that Meta is working hard to reclaim its spot at the front.
Using key data points presented in three tables, this post provides a quick overview of how Llama’s architecture evolved over the past three years, focusing on its release timeline, the scaling and choices of its technical architecture, and how its choices stack up against its major competitors.
Table 1: Release Timeline

Highlights from Table 1
Rapid Iteration and Increasing Specialization: The Llama 3 generation saw accelerated point releases (3.1, 3.2, 3.3) within months in 2024, indicating a shift towards faster, more diverse model rollouts supporting coding, vision, edge deployments etc.
Shift to Openness with Open Weights: Llama 1 started as a restricted research release, but Llama 2 marked a pivot towards broader commercial use, a strategy continued with subsequent versions, albeit with some restrictive licensing conditions.
Architectural Leaps: Llama 4 introduced fundamental changes like Mixture of Experts (MoE) and native multimodality, distinguishing it significantly from the Llama 1-3 generations.
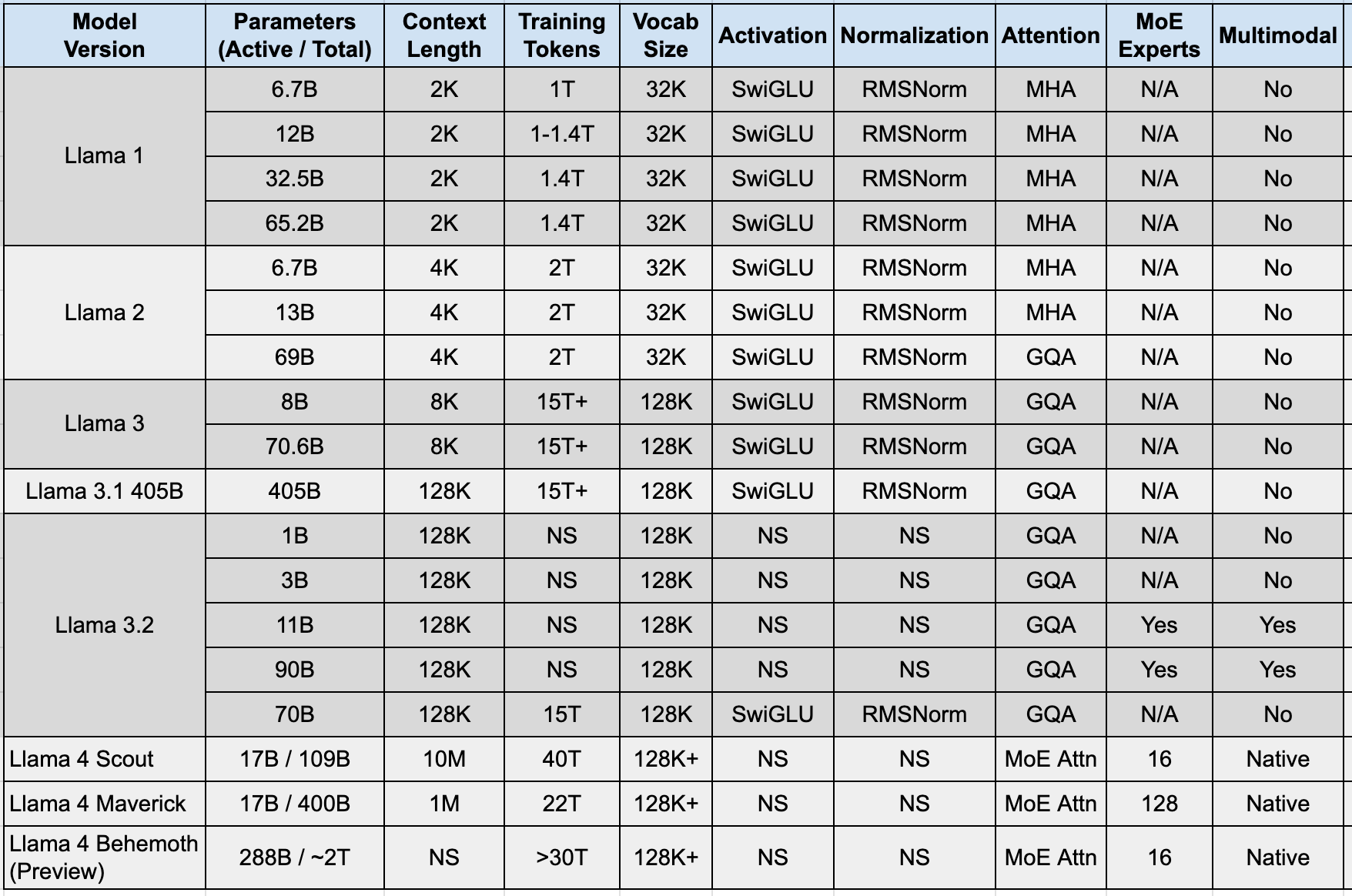
Table 2: Detailed Technical Specifications Comparison
*Note: NS = Not Specified in provided sources.
Highlights from Table 2
Exponential Growth in Context Length: Context window size saw dramatic increases, from 2K in Llama 1 to 128K in Llama 3.1, and finally increasing to 1M/10M in Llama 4.
Massive Training Data Scaling: The volume of training data grew exponentially as well, from ~1.4T tokens for Llama 1 to 15T+ for Llama 3, and up to ~40T for Llama 4 Scout.
Architectural Refinements: Key changes include the adoption of RMSNorm and SwiGLU from Llama 1 onwards; the introduction of Grouped Query Attention (GQA) in Llama 2 (70B) and its standardization across Llama 3 models; and the shift to a much larger 128K+ vocabulary tokenizer from Llama 3 onwards.
Shift to Mixture of Experts (MoE): Llama 4 introduced MoE, decoupling active parameters (used per token, e.g., 17B) from total parameters (overall knowledge, e.g., 109B), aiming for greater efficiency at scale.
Multimodality Integration: While Llama 3.2 added vision capabilities, Llama 4 implemented native multimodality from the ground up.
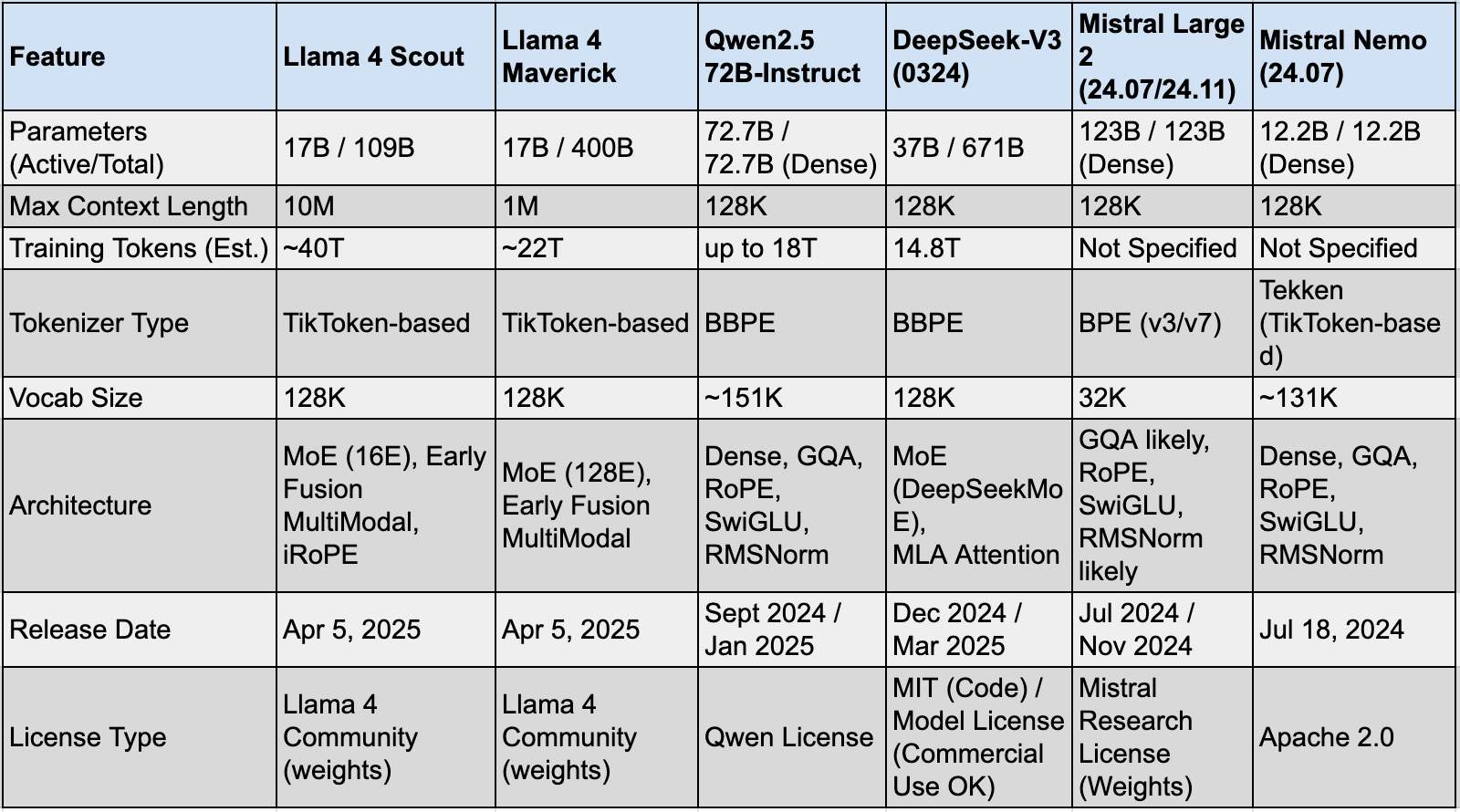
Table 3: Comparative Technical Specifications (as of April 2025)
Highlights from Table 3
Architectural Diversity: Llama 4 and DeepSeek V3 utilize MoE architectures, while Qwen 2.5 and Mistral Large 2/Nemo stick to dense designs, showcasing different strategies for scaling. MoE models (Llama 4, DeepSeek V3) have lower active parameters compared to dense models (Qwen2.5, Mistral Large 2) of similar capability, aiming for inference, but differ in their active/total parameter ratios.
Context Length: Llama 4 Scout (10M) and Maverick (1M) offer significantly larger context windows than the 128K standard supported by Qwen 2.5, DeepSeek V3, and Mistral Large 2/Nemo.
Tokenizer Variations: Vocabulary sizes and tokenizer types vary, with Llama 4, DeepSeek V3, and Mistral Nemo using larger vocabularies (~128K-131K) compared to Mistral Large 2 (32K). Qwen 2.5 has the largest vocab (~151K).
Licensing Fragmentation: Licensing terms differ significantly, from the permissive Apache 2.0 (Mistral Nemo) and MIT/Commercial (DeepSeek V3) to custom licenses with MAU restrictions (Llama 4, Qwen 2.5) and research-focused licenses (Mistral Large 2 weights).
«That’s all folks! Hope you got something out of this one :)»